

Содержание
Окислительно-восстановительные реакции (ОВР) — что это такое? Примеры и реакции
Что такое ОВР
Окислительно-восстановительная реакция (ОВР) — это реакция, которая протекает с изменением степеней окисления.
В такой реакции всегда участвуют вещество-окислитель и вещество-восстановитель. Другие вещества могут выступать в качестве среды, в которой протекает данная реакция.
Конечно, в каждом правиле есть исключения. Например, реакция диспропорционирования галогенов в горячем растворе щелочи выглядит так: Br2 + KOH = KBrO3 + KBr + H2O. Здесь и окислителем, и восстановителем является простое вещество бром (Br2).
Теперь посмотрим внимательнее на вещества — участники окислительно-восстановительных реакций.
Окислитель — вещество, в состав которого входит ион или атом, который в процессе реакции будет принимать электроны, тем самым понижая свою степень окисления.
Восстановитель — вещество, в состав которого входит ион или атом, который в процессе реакции будет отдавать электроны, тем самым повышая свою степень окисления.
Из определений понятно, что реакция включает два противоположных по действиям явления: процесс окисления и процесс восстановления. Процесс восстановления — это процесс принятия электронов, а процесс окисления — процесс отдачи электронов. Оба процесса протекают одновременно: окислитель восстанавливается, а восстановитель окисляется.
Вот мы и узнали общие закономерности протекания окислительно-восстановительных реакций. Теперь давайте разберемся, какие вещества могут быть окислителями, а какие — восстановителями, и может ли одно вещество проявлять те и другие свойства.
Твоя пятёрка по английскому.
С подробными решениями домашки от Skysmart
Примеры веществ-окислителей
Только окислителями могут быть элементы в высшей своей степени окисления. Например, S+6 в серной кислоте (H2SO4), N+5 в азотной кислоте (HNO3) или солях-нитратах, Cr+6 в хроматах (CrO42−) и дихроматах (Cr2O72−) соответственно, а также Mn+7 (MnO4−).
Например, S+6 в серной кислоте (H2SO4), N+5 в азотной кислоте (HNO3) или солях-нитратах, Cr+6 в хроматах (CrO42−) и дихроматах (Cr2O72−) соответственно, а также Mn+7 (MnO4−).
В зависимости от среды проведения реакции Mn+7 и Cr+6 ведут себя по-разному. Рассмотрим на схемах:
И марганец, и хром в кислой среде (H+) образуют соли той кислоты, которая образовывала среду. В нейтральной среде (H2O) марганец превращается в оксид бурого цвета, а хром — в серо-зеленый нерастворимый в воде гидроксид. В щелочной среде (OH−) марганец превращается в манганат (MnO42−), а хром — в комплексное соединение светло-зеленого цвета.
Только окислителями могут быть простые вещества-неметаллы. Например, представители VIIA группы — галогены. Проявляя окислительные свойства в кислой среде, галогены восстанавливаются до соответствующих им галогеноводородных кислот: HF, HCl, HBr, HI. В щелочной среде образуются соли галогеноводородных кислот.
Например, представители VIIA группы — галогены. Проявляя окислительные свойства в кислой среде, галогены восстанавливаются до соответствующих им галогеноводородных кислот: HF, HCl, HBr, HI. В щелочной среде образуются соли галогеноводородных кислот.
Кислород превращается в анион с устойчивой степенью окисления −2. А сера ведет себя как окислитель по отношению к водороду и металлам, образуя при этом сероводород и сульфиды.
Только окислителями могут быть и протон водорода (H+) и катионы металлов в их высших степенях окисления при нескольких возможных. Ион Н+ при взаимодействии с восстановителями переходит в газообразный водород (H2), а катионы металлов — в ионы с более низкой степенью окисления: 2CuCl2 + 2KI = CuCl + 2KCl + I2.
Рассмотрим как ведут себя сильные кислоты-окислители — азотная и серная. В зависимости от их концентрации меняются и продукты реакции.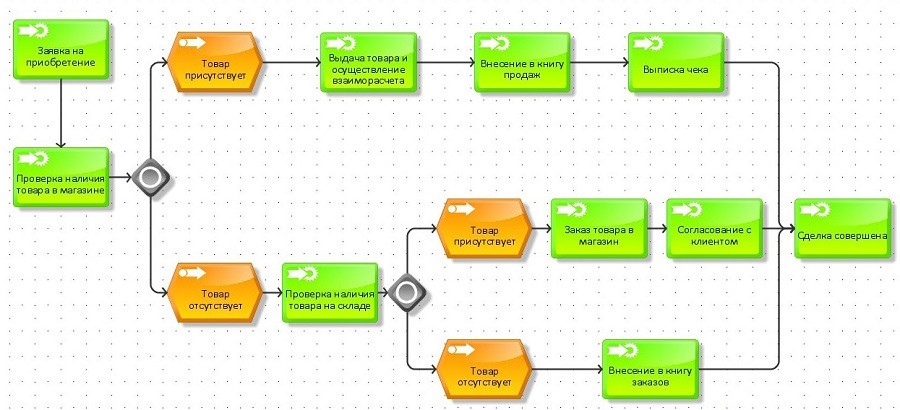
Запоминаем!
Разбавленная азотная кислота никогда не реагирует с металлами с выделением водорода в отличие от разбавленной серной кислоты. Обе эти кислоты реагируют с металлами, стоящими в ряду активности после водорода.
Эти кислоты проявляют окислительные способности и с некоторыми неметаллами, окисляя их до соответствующих кислот в высшей степени окисления неметалла-восстановителя.
Для удобства мы собрали цвета переходов важнейших веществ-окислителей в одном месте.
Примеры веществ-восстановителей
Типичными восстановителями могут быть щелочные (IA) и щелочноземельные (IIA) металлы, цинк и алюминий, а также катионы металлов в своих низших степенях окисления при нескольких возможных. Например:
Fe + H2SO4 (разб) = FeSO4 + H2
6СuCl + K2Cr2O7 + 14HCl (разб) = 6CuCl2 + 2CrCl3 + 2KCl + 7H2O.
Типичными восстановителями также могут быть бескислородные кислоты и их соли. Например, H2S + 4Cl2 + 4H2O = 8HCl + H2SO4.
Гидриды активных металлов (щелочных и щелочноземельных) тоже являются типичными восстановителями. Например, NaH + H2O = NaOH + H2.
Для удобства мы собрали цвета переходов важнейших веществ-восстановителей в одном месте.
Окислительно-восстановительная двойственность
Окислительно-восстановительная двойственность — это способность атома проявлять как свойства окислителя, так и свойства восстановителя в зависимости от условия протекания химической реакции.
Разберем вещества, атомы которых обладают окислительно-восстановительной двойственностью.
Сера
По отношению к водороду и металлам сера играет роль окислителя: S + H2 = H2S.
При взаимодействии с сильными окислителями повышает свою степень окисления до +4 или +6: S + KMnO4 = K2SO4 + MnO2.
Кислородсодержащие соединения серы в степени окисления +4
Сера в сульфитах и сернистой кислоте при взаимодействии с сильными окислителями повышает степень окисления до +6: SO2 + 2HNO3 (конц) = H2SO4 + 2NO2.
С восстановителями соединения серы проявляют окислительные свойства, восстанавливаясь до степени окисления 0 или −2: SO2 + C = CO2 + S.
Пероксид водорода
Атом кислорода в пероксиде водорода находится в промежуточной степени окисления –1, и в присутствии восстановителей может понижать степень окисления до –2: 4H2O2 + PbS = PbSO4 + 4H2O.
Атом кислорода в пероксиде водорода находится в промежуточной степени окисления –1, и в присутствии окислителей может повышать степень окисления до 0: 3H2O2 + 2KMnO4 = 3O2 + 2MnO2 + 2KOH + 2H2O.
Простое вещество йод
Окислительная способность проявляется у йода в реакции с такими восстановителями, как сероводород, фосфор и металлы: I2 + H2S = S + 2HI.
Йод при взаимодействии с более сильными окислителями играет роль восстановителя: I2 + 5Cl2 + 6H2O = 2HIO3 + 10HCl.
Азотистая кислота и нитриты
При взаимодействии с более сильными окислителями азот повышает степень окисления до +5 и превращается либо в азотную кислоту из азотистой, либо в нитрат-анион из нитрит-аниона: 5NaNO2 + 2KMnO4 + 3H2SO4 = 5NaNO3 + 2MnSO4 + K2SO4 + 3H2O.
При взаимодействии с сильными восстановителями обычно происходит восстановление до NO (иногда до других соединений азота в более низких степенях окисления): 2HNO2 + 2HI = 2NO + I2 + 2H2O.
Для удобства мы собрали представителей типичных окислителей и восстановителей в одну схему.
Классификация окислительно-восстановительных реакций
Окислительно-восстановительные реакции можно поделить на четыре типа:
межмолекулярные ОВР;
внутримолекулярные ОВР;
реакции диспропорционирования;
реакции контрпропорционирования.
Рассмотрим каждую по отдельности.
Межмолекулярная ОВР — это реакция, окислитель и восстановитель которой являются различными веществами.
2KI + Br2 = 2KBr + I2, где Br2 — окислитель, а KI — восстановитель (за счёт I−1).
Внутримолекулярная ОВР — это реакция, в которой один атом является окислителем, а другой восстановителем в рамках одного соединения.
Пример такой окислительно-восстановительной реакции:
где Cl+5 — окислитель, а O−2 — восстановитель.
Термическое разложение нитратов — это внутримолекулярная ОВР. Вот схема разложения нитратов в зависимости от металла, входящего в состав соли.
Исключение — разложение нитрата железа (II): 4Fe(NO3)2 = 2Fe2O3 + 8NO2 + O2. Здесь железо окисляется до +3 вопреки правилам. Иначе разлагается при нагревании и нитрат аммония: NH4NO3 = N2O + 2H2O.
Окислительно-восстановительная реакция диспропорционирования — это реакция, в ходе которой один и тот же атом является и окислителем, и восстановителем. Например, 3HNO2 = HNO3 + 2NO + H2O, где N+3 переходит в N+5, являясь восстановителем, и N+3 переходит в N+2, являясь окислителем.
Окислительно-восстановительная реакция контрпропорционирования — это реакция, в которой атомы одного и того же химического элемента в разных степенях окисления входят в состав разных веществ, при этом образуя новые молекулы одного и того же продукта.
Основные правила составления ОВР
Подобрать среди исходных веществ окислитель и восстановитель, а также вещество, которое отвечает за среду — при необходимости. Для этого нужно расставить степени окисления элементов и сравнить их окислительно-восстановительные свойства.
Составить уравнение реакции и записать продукты реакции. Следует помнить, что в кислой среде образуются соли одно-, двух- и трехзарядных катионов, а для создания среды чаще всего используют серную кислоту. В кислой среде невозможно образование оснóвных оксидов и гидроксидов, так как они вступят в реакцию с кислотой.
 В щелочной среде не могут образовываться кислоты и кислотные оксиды, а образуются соли.
В щелочной среде не могут образовываться кислоты и кислотные оксиды, а образуются соли.Уравнять методом электронного баланса или методом полуреакций.
Составим алгоритм для уравнивания окислительно-восстановительных реакций методом электронного баланса.
Главное условие протекания ОВР — общее число электронов, отданных восстановителем, должно быть равно общему числу электронов, принятых окислителем.
Определите атомы, которые меняют свои степени окисления в ходе реакции.
Выпишите, сколько электронов принял окислитель и отдал восстановитель. Если восстановителей несколько, выписываем все.
Найдите НОК для суммарно отданных/принятых электронов.
Расставьте первые полученные коэффициенты перед окислителем и одним или несколькими восстановителями.
Уравняйте все присутствующие металлы в уравнении реакции.
Уравняйте кислотные остатки.
Уравняйте водород — в обеих частях его должно быть одинаковое количество.
Проверьте себя по кислороду — если все посчитано верно, то он сойдется.
 В щелочной среде не могут образовываться кислоты и кислотные оксиды, а образуются соли.
В щелочной среде не могут образовываться кислоты и кислотные оксиды, а образуются соли.
Ускоренное восстановление базы данных — Azure SQL
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 6 мин
-
Область применения:База данных SQL Azure Управляемый экземпляр SQL Azure
Ускоренное восстановление баз данных (ADR) — это функция ядра СУБД SQL Server, которая значительно повышает доступность базы данных, особенно при наличии длительных транзакций, изменяя процесс восстановления ядра СУБД SQL Server.
В настоящее время ADR доступна для Базы данных SQL Azure, Управляемого экземпляра SQL Azure, баз данных в Azure Synapse Analytics и SQL Server на виртуальных машинах Azure, начиная с SQL Server 2019. Дополнительные сведения об ADR в SQL Server см. в статье Управление ускоренным восстановлением базы данных.
Примечание
ADR включается по умолчанию в Базе данных SQL Azure и Управляемом экземпляре SQL Azure. Отключение ADR в Базе данных SQL Azure и Управляемом экземпляре Azure SQL не поддерживается.
Обзор
Основные преимущества ADR
Быстрое и согласованное восстановление баз данных
При использовании ADR длительные транзакции не влияют на общее время восстановления, благодаря чему обеспечивается быстрое и согласованное восстановление базы данных независимо от количества активных транзакций в системе или их размеров.
Мгновенный откат транзакции
При использовании ADR откат транзакций совершается мгновенно независимо от времени активности транзакции или количества выполненных обновлений.
Агрессивное усечение журнала
При использовании ADR журнал транзакций агрессивно усекается даже при наличии активных длительных транзакций, что предотвращает неконтролируемое увеличение его размера.
Стандартный процесс восстановления базы данных
Восстановление базы данных соответствует модели восстановления ARIES и состоит из трех этапов, которые проиллюстрированы на следующей схеме. Их подробное описание представлено ниже.
Стадия анализа
Прямой просмотр журнала транзакций, начиная с последней успешной контрольной точки (или регистрационного номера транзакции в журнале для самой старой «грязной» страницы) и до конца, для определения состояния каждой транзакции на момент остановки базы данных.
Стадия повтора
Прямой просмотр журнала транзакций, начиная с самой старой незафиксированной транзакции и до конца, для повтора всех зафиксированных операций и возврата базы данных в то состояние, в котором она находилась на момент сбоя.
Стадия отката
В каждой транзакции, которая была активна на момент сбоя, происходит перемещение по журналу назад и отменяются операции, выполненные в ходе этой транзакции.
Исходя из этой схемы, время, необходимое ядру СУБД SQL Server для восстановления после неожиданного перезапуска, (примерно) пропорционально размеру самой продолжительной активной транзакции в системе во время сбоя. Для восстановления требуется откат всех незавершенных транзакций. Необходимое время пропорционально объему работы, выполненному транзакцией, и времени ее активности. Таким образом, при наличии длительных транзакций (например, больших операций массовой вставки или операций построения индекса для большой таблицы) процесс восстановления может занимать много времени.
Кроме того, отмена или откат большой транзакции по этой схеме также может занять много времени, так как используется та же самая стадия восстановления (стадия отката), как описано выше.
Кроме того, ядро СУБД SQL Server не может усечь журнал транзакций при длительных транзакциях, так как соответствующие записи журнала требуются для процессов восстановления и отката. Из-за этих особенностей ядра СУБД SQL Server некоторые клиенты сталкивались со следующей проблемой: размер журнала транзакций становился очень большим и занимал слишком много места на диске.
Процесс ускоренного восстановления базы данных
Функция ADR позволяет решить вышеуказанные проблемы, так как она полностью меняет процесс восстановления ядра СУБД SQL Server следующим образом:
- Процесс длится фиксированное время или производится мгновенно благодаря тому, что не приходится проверять журнал от начала самой старой активной транзакции. При использовании ADR журнал транзакций обрабатывается только от последней успешной контрольной точки (или регистрационного номера транзакции в журнале для самой старой «грязной» страницы). В результате длительные транзакции не влияют на время восстановления.
- Уменьшается место, которое требуется для журнала транзакций, так как больше не нужно обрабатывать журнал для всей транзакции. В результате журнал транзакций может агрессивно усекаться при наличии контрольных точек и резервных копий.
На самом общем уровне ADR обеспечивает быстрое восстановление баз данных благодаря управлению версиями всех физических изменений базы данных и отмене только логических операций, которая может производиться почти мгновенно. Любая транзакция, которая была активна на момент сбоя, помечается как прерванная, и поэтому любые версии, созданные такими транзакциями, могут быть проигнорированы в параллельных запросах пользователей.
Процесс восстановления ADR состоит из тех же трех этапов, что и текущий процесс восстановления. Этапы восстановления ADR проиллюстрированы на следующей схеме, а их подробное описание представлено ниже.
Стадия анализа
Процесс остается таким же, но при этом воссоздается SLOG и копируются записи журнала для операций без версий.
Стадия повтора
Эта стадия разделена на два этапа.
Этап 1
Повтор из SLOG (от самой старой незафиксированной транзакции до последней контрольной точки). Повтор — это быстрая операция, так как требует обработки всего нескольких записей из SLOG.
Этап 2
Повтор в журнале транзакций начинается с последней контрольной точки (вместо самой старой незафиксированной транзакции).
Стадия отката
Стадия отката при использовании ADR выполняется практически мгновенно благодаря применению SLOG для отката операций без версий и постоянного хранилища версий (PVS) с логической отменой изменений для отката на основе версий на уровне строк.

Компоненты восстановления ADR
Ниже приведены четыре основных компонента ADR.
Постоянное хранилище версий (PVS)
Постоянное хранилище версий — это новый механизм ядра СУБД SQL Server для хранения версий строк, созданных в базе данных, вместо традиционного хранилища версий
tempdb. PVS позволяет изолировать ресурсы, а также повышает доступность получателей, доступных для чтения.Логическая отмена изменений
Логическая отмена изменений — это асинхронный процесс отмены действий на основе версий на уровне строк. Он обеспечивает мгновенный откат транзакций и отмену операций с управлением версиями. Для логической отмены изменений применяются следующие механизмы:
- Отслеживание всех прерванных транзакций и их маркировка их как невидимых для других транзакций.
- Выполнение отката с применением персистентного хранилища версий для всех пользовательских транзакций вместо физического сканирования журнала транзакций и отмены изменений по одному за раз.
- Немедленное снятие всех блокировок в случае прерывания транзакции. Так как прерывание выполняется путем простой маркировки изменений в памяти, этот процесс очень эффективен и не требует длительного сохранения блокировок.
SLOG
SLOG — это дополнительный поток журнала в памяти, в котором хранятся записи журнала для операций без версий (таких как перевод кэша метаданных в недействительное состояние, получение блокировки и пр.
). Характеристики SLOG:- малый объем и размещение в памяти;
- сохраняется на диске путем сериализации во время обработки контрольных точек;
- периодическое усекается при фиксации транзакций;
- ускоряет повтор и отмену благодаря обработке только операций без версий;
- обеспечивает агрессивное усечение журнала транзакций за счет сохранения только необходимых записей журнала.
Очистка
Очистка — это асинхронный процесс, который периодически активируется и очищает ненужные версии страниц.
 PVS позволяет изолировать ресурсы, а также повышает доступность получателей, доступных для чтения.
PVS позволяет изолировать ресурсы, а также повышает доступность получателей, доступных для чтения. ). Характеристики SLOG:
). Характеристики SLOG:Шаблоны ускоренного восстановления базы данных (ADR)
Использование ADR дает наилучший результат для следующих типов рабочих нагрузок:
- ADR рекомендуется использовать для рабочих нагрузок с длительными транзакциями.
- ADR рекомендуется использовать для рабочих нагрузок, если возникали проблемы со значительным увеличением размера журнала транзакций из-за активных транзакций.
- ADR рекомендуется использовать для рабочих нагрузок, если случались длительные периоды недоступности баз данных из-за длительного процесса восстановления (например, вследствие непредвиденного перезапуска службы или отката транзакций вручную).

Рекомендации по использованию Ускоренного восстановления баз данных
Избегайте выполнения длительных транзакций в базе данных. Хотя одной из задач ADR является ускорение восстановления базы данных из-за длительных активных транзакций, выполнение таких транзакций может привести к задержке очистки версий и увеличению размера постоянного хранилища версий.
Избегайте больших транзакций с изменениями определений данных или операциями DDL. ADR использует механизм SLOG (системный журнал потока) для трассировки операций DDL, используемых при восстановлении. SLOG используется, только если транзакция активна. SLOG имеет контрольные точки, поэтому, избегая выполнения больших транзакций, использующих SLOG, вы можете повысить общую производительность. Эти сценарии могут привести к тому, что SLOG займет больше места:
Многие DDL выполняются в рамках одной транзакции. Например, в рамках одной транзакции быстро создаются и удаляются временные таблицы.
Таблица имеет очень большое количество изменяемых секций или индексов. Например, при выполнении операции DROP TABLE для такой таблицы потребуется большое резервирование памяти SLOG, что приведет к задержке усечения журнала транзакций и задержке операций отмены и повтора. Проблему можно решить, удаляя индексы по отдельности и постепенно с последующим удалением таблицы. Дополнительные сведения о SLOG см. в статье Компоненты восстановления ADR.
Предотвратите или уменьшите число ненужных ситуаций с прерыванием. Высокая частота прерываний негативно влияет на очистку PVS и снижает производительность ADR. Прерывания могут возникать из-за большого количества взаимоблокировок, дублирования ключей или других нарушений ограничений.
DMV
sys.dm_tran_aborted_transactionsотображает все прерванные транзакции в экземпляре SQL Server. В столбцеnested_abortуказано, что транзакция зафиксирована, но есть прерванные части (точки сохранения или вложенные транзакции), которые могут заблокировать процесс очистки PVS. Дополнительные сведения см. в статье sys.dm_tran_aborted_transactions (Transact-SQL).Чтобы активировать процесс очистки PVS вручную между рабочими нагрузками или во время периодов обслуживания, используйте
sys.sp_persistent_version_cleanup. Дополнительные сведения см. в статье sys.sp_persistent_version_cleanup.
При возникновении проблем с использованием хранилища, частыми прерываниями транзакций и другими факторами, см. статью Устранение неполадок с Ускоренным восстановлением базы данных (ADR) в SQL Server.

 Дополнительные сведения см. в статье sys.dm_tran_aborted_transactions (Transact-SQL).
Дополнительные сведения см. в статье sys.dm_tran_aborted_transactions (Transact-SQL).Дальнейшие действия
- Ускоренное восстановление баз данных
- Устранение неполадок с Ускоренным восстановлением базы данных (ADR) в SQL Server.
11 класс. Химия. Окислительно-восстановительные реакции — Окислительно-восстановительные реакции
Комментарии преподавателя
1. Понятие ОВР, определение окислителей и восстановителей
Реакции, протекающие с изменением степеней окисления атомов, входящих в состав реагирующих веществ, называются окислительно-восстановительными. Изменение степеней окисления происходит из-за перехода электронов от восстановителя к окислителю. Степень окисления – это формальный заряд атома, если считать, что все связи в соединении являются ионными.
Изменение степеней окисления происходит из-за перехода электронов от восстановителя к окислителю. Степень окисления – это формальный заряд атома, если считать, что все связи в соединении являются ионными.
Окислитель – это вещество, молекулы или ионы которого принимает электроны. Если элемент является окислителем, его степень окисления понижается.
О02 +4е-→ 2О-2 (Окислитель, процесс восстановления)
Процесс приема веществами электронов называется восстановлением. Окислитель в ходе процесса восстанавливается.
Восстановитель – это вещество, молекулы или ионы которого отдают электроны. У восстановителя степень окисления повышается.
S0 -4е- →S+4 (Восстановитель, процесс окисления)
Процесс отдачи электронов называется окислением. Восстановитель в ходе процесса окисляется.
2. Составление схемы электронного баланса
Пример №1. Получение хлора в лаборатории
В лаборатории хлор получают из перманганата калия и концентрированной соляной кислоты. В колбу Вюрца помещают кристаллы перманганата калия. Закрывают колбу пробкой с капельной воронкой. В воронку наливается соляная кислота. Соляная кислота приливается из капельной воронки. Сразу же начинается энергичное выделение хлора. Через газоотводную трубку хлор постепенно заполняет цилиндр, вытесняя из него воздух. Рис. 1.
В колбу Вюрца помещают кристаллы перманганата калия. Закрывают колбу пробкой с капельной воронкой. В воронку наливается соляная кислота. Соляная кислота приливается из капельной воронки. Сразу же начинается энергичное выделение хлора. Через газоотводную трубку хлор постепенно заполняет цилиндр, вытесняя из него воздух. Рис. 1.
Рис. 1
На примере этой реакции рассмотрим, как составлять электронный баланс.
1. Запишем схему этой реакции:
KMnO4 + HCI = KCI + MnCI2 + CI2 + h3O
2. Расставим степени окисления всех элементов в веществах, участвующих в реакции:
K+Mn+7O-24 + H+CI- = K+CI- + Mn+2CI-2 + CI02 + H+2O-2
Степени окисления поменяли марганец и хлор.
3. Составляем схему, отражающую процесс перехода электронов:
Mn+7+5е- = Mn+2 окислитель, процесс восстановление
2 CI- -2е- = CI02 восстановитель, процесс окисление
4. Уравняем число отданных и принятых электронов. Для этого находим наименьшее общее кратное для чисел 5 и 2. Это 10. В результате деления наименьшего общего кратного на число отданных и принятых электронов, находим коэффициенты перед окислителем и восстановителем.
Это 10. В результате деления наименьшего общего кратного на число отданных и принятых электронов, находим коэффициенты перед окислителем и восстановителем.
Mn+7+5е- = Mn+2 2
2 CI- -2е- = CI02 5
5. Переносим коэффициенты в исходную схему и преобразуем уравнение реакции.
2KMnO4 + ? HCI = ?KCI + 2MnCI2 + 5CI2 +? h3O
Однако перед формулой соляной кислоты не поставлен коэффициент, так как не все хлоридные ионы участвовали в окислительно-восстановительном процессе. Метод электронного баланса позволяет уравнивать только ионы, участвующие в окислительно-восстановительном процессе. Поэтому нужно уравнять количество ионов, не участвующих в окислительно-восстановительной реакции. А именно катионов калия, водорода и хлоридных анионов. В результате получается следующее уравнение:
2KMnO4 + 16 HCI = 2KCI + 2MnCI2 + 5CI2 + 8h3O
Пример №2. Взаимодействие меди с концентрированной азотной кислотой. Рис. 2.
В стакан с 10 мл кислоты поместили «медную» монету. Быстро началось выделение бурого газа (особенно эффектно выглядели бурые пузырьки в еще бесцветной жидкости). Все пространство над жидкостью стало бурым, из стакана валили бурые пары. Раствор окрасился в зеленый цвет. Реакция постоянно ускорялась. Примерно через полминуты раствор стал синим, а через две минуты реакция начала замедляться. Монета полностью не растворилась, но сильно потеряла в толщине (ее можно было изогнуть пальцами). Зеленая окраска раствора в начальной стадии реакции обусловлена продуктами восстановления азотной кислоты.
Быстро началось выделение бурого газа (особенно эффектно выглядели бурые пузырьки в еще бесцветной жидкости). Все пространство над жидкостью стало бурым, из стакана валили бурые пары. Раствор окрасился в зеленый цвет. Реакция постоянно ускорялась. Примерно через полминуты раствор стал синим, а через две минуты реакция начала замедляться. Монета полностью не растворилась, но сильно потеряла в толщине (ее можно было изогнуть пальцами). Зеленая окраска раствора в начальной стадии реакции обусловлена продуктами восстановления азотной кислоты.
Рис. 2
1. Запишем схему этой реакции:
Cu + HNO3 = Cu (NO3)2 + NO2↑ + h3O
2. Расставим степени окисления всех элементов в веществах, участвующих в реакции:
Cu0 + H+N+5O-23 = Cu+2(N+5O-23)2 + N+4O-22↑ + H+2O-2
Степени окисления поменяли медь и азот.
3. Составляем схему, отражающую процесс перехода электронов:
N+5+е- = N+4 окислитель, процесс восстановление
Cu0 -2е- = Cu+2 восстановитель, процесс окисление
4. Уравняем число отданных и принятых электронов. Для этого находим наименьшее общее кратное для чисел 1 и 2. Это 2. В результате деления наименьшего общего кратного на число отданных и принятых электронов, находим коэффициенты перед окислителем и восстановителем.
Уравняем число отданных и принятых электронов. Для этого находим наименьшее общее кратное для чисел 1 и 2. Это 2. В результате деления наименьшего общего кратного на число отданных и принятых электронов, находим коэффициенты перед окислителем и восстановителем.
N+5+е- = N+4 2
Cu0 -2е- = Cu+2 1
5. Переносим коэффициенты в исходную схему и преобразуем уравнение реакции.
Cu + ?HNO3 = Cu (NO3)2 + 2NO2↑ + 2h3O
Азотная кислота участвует не только в окислительно-восстановительной реакции, поэтому коэффициент сначала не пишется. В результате, окончательно получается следующее уравнение:
Cu + 4HNO3 = Cu (NO3)2 + 2NO2↑+ 2h3O
3. Классификация ОВР
Классификация окислительно-восстановительных реакций
1. Межмолекулярные окислительно-восстановительные реакции.
Это реакции, в которых окислителем и восстановителем являются разные вещества.
Н2S-2 + Cl02 → S0 + 2HCl-
2. Внутримолекулярные реакции, в которых окисляющиеся и останавливающиеся атомы находятся в молекулах одного и того же вещества, например:
2H+2O-2 → 2H02 + O02
3. Диспропорционирование (самоокисление-самовосстановление) – реакции, в которых один и тот же элемент выступает и как окислитель, и как восстановитель, например:
Диспропорционирование (самоокисление-самовосстановление) – реакции, в которых один и тот же элемент выступает и как окислитель, и как восстановитель, например:
Cl02 + h3O → HCl+O + HCl-
4. Конпропорционирование (Репропорционирование) – реакции, в которых из двух различных степеней окисления одного и того же элемента получается одна степень окисления
5. N-3h5N+5O3 → N+2O + 2h3O
4/ Факторы, влияющие на продукты окисления
Факторы, влияющие на конечные продукты реакции
При протекании окислительно-восстановительных реакций, конечные продукты зависят от многих факторов.
· Состав реагирующих веществ
· Температура
· Концентрация
· Кислотность среды
ИСТОЧНИКИ
источник видео — http://www.youtube.com/watch?v=l2j57kNSLEk
источник видео — http://www.youtube.com/watch?v=bz65sRqJUjQ
источник презентации — http://ppt4web. ru/khimija/okislitelnovosstanovitelnye-reakcii3.html
ru/khimija/okislitelnovosstanovitelnye-reakcii3.html
http://interneturok.ru/ru/school/chemistry/11-klass — конспект
Для скачивания — Кафедра химии
- Главная
- Университет
- Для скачивания
- Кафедра химии
Лекция. Растворы неэлектролитов
Размер файла:
638.79 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:03
Растворы неэлектролитов. Лекция по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ , 2016. – 33 с.
Учебно-методическое пособие включает лекцию по теме «Растворы неэлектролитов» курса «Общая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование пособия, в котором рассмотрены важнейшие теоретические вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Лекция. Окислительно-восстановительные реакции
Размер файла:
609. 98 kB
98 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:03
Окислительно – восстановительные реакции. Лекция по курсу «Общая химия » для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 31 с.
Учебно-методическое пособие включает лекцию по теме «Окислительно – восстановительные реакции» и предназначено для контролируемой самостоятельной работы студентов инженерно–технологического факультета. Использование такого пособия, в котором рассмотрены важнейшие вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Лекция. Комплексные соединения
Размер файла:
531.46 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:03
Лекция «Комплексные соединения» по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 26 с.
Учебно-методическое пособие включает лекцию по теме «Комплексные соединения» курса «Общая химия». Комплексные соединения играют важную роль в природе и технике, прежде всего, это ферментативные и фотохимические процессы, перенос кислорода в биологических системах, тонкая технология редких металлов, каталитические реакции и т.д. Координационные свойства проявляются всеми элементами периодической системы.
Комплексные соединения играют важную роль в природе и технике, прежде всего, это ферментативные и фотохимические процессы, перенос кислорода в биологических системах, тонкая технология редких металлов, каталитические реакции и т.д. Координационные свойства проявляются всеми элементами периодической системы.
Скачать
Лекция. Кинетика химических реакций. Химическое равновесие
Размер файла:
768.32 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:03
Кинетика химических реакций. Химическое равновесие. Лекции по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 44 с.
Учебно-методическое пособие включает лекции по отдельным темам курса «Общая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование таких пособий, в которых рассмотрены важнейшие теоретические вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Предэкзаменационные тесты по органической и биологической ХИМИИ
Размер файла:
1.30 MB
Автор:
Макарчиков А.Ф., Колос И.К.
Дата:
26.12.2016 12:02
Предэкзаменационные тесты по органической и биоло-гической химии для студентов биотехнологического факультета / А.Ф. Макарчиков, И.К. Колос – Гродно: ГГАУ, 2016. – 205 с.
В пособии приведен перечень вопросов для проведения предэкзаменационного тестирования студентов, обучающихся на биотехнологическом факультете, по предмету «Химия (органическая и биологическая)»
Скачать
Лекция. Электролиз. Коррозия металлов и методы защиты металлов от коррозии
Размер файла:
758.87 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:02
Электролиз. Коррозия металлов и методы защиты металлов от коррозии. Лекция по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 31 с.
Учебно-методическое пособие включает лекции по отдельным темам курса «Общая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование таких пособий, в которых рассмотрены важнейшие теоретические вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Использование таких пособий, в которых рассмотрены важнейшие теоретические вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Лекция. Энергетика химических процессов.
Размер файла:
604.00 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:02
Энергетика химических процессов. Лекция по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 25 с.
Учебно-методическое пособие включает лекцию по теме «Энергетика химических процессов» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование такого пособия, в котором рассмотрены важнейшие вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Лекция. Строение атомов элементов
Размер файла:
789.90 kB
Автор:
Апанович, З.В.
Дата:
26. 12.2016 12:02
12.2016 12:02
Строение атомов элементов. Лекция по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ , 2016. – 23 с.
Учебно-методическое пособие включает лекцию по теме «Строение атомов элементов» курса «Общая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование пособия, в котором рассмотрены важнейшие теоретические вопросы в доступной и сжатой форме, позволит студентам быстрее и эффективнее изучить материал.
Скачать
Лекция. Основные понятия и законы химии
Размер файла:
675.23 kB
Автор:
Апанович, З.В.
Дата:
26.12.2016 12:03
Основные понятия и законы химии. Лекция по курсу «Общая химия» для студентов инженерно-технологического факультета / З.В. Апанович. – Гродно : ГГАУ, 2016. – 30 с.
Учебно-методическое пособие включает лекцию по теме «Основные понятия и законы химии» курса «Общая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета. Использование студентами распечатки лекционной темы значительно сэкономит время для понимания материала, излагаемого лектором, и конспектирования.
Использование студентами распечатки лекционной темы значительно сэкономит время для понимания материала, излагаемого лектором, и конспектирования.
Скачать
Предэкзаменационные тесты по химии
Размер файла:
813.02 kB
Автор:
Макарчиков А.Ф., Колос И.К.
Дата:
14.11.2016 11:47
Предэкзаменационные тесты по химии для студентов, обучающихся на агробиологических специальностях / А.Ф. Макарчиков, И.К. Колос – Гродно: ГГАУ, 2016. – 201 с.
В пособии приведен перечень вопросов для проведения предэкзаменационного тестирования студентов, обучающихся на агробиологических специальностях, по предмету «Химия».
Скачать
Методическое пособие для лабораторных работ по аналитической химии
Размер файла:
544.41 kB
Автор:
Апанович З.В., Тараненко Т.В., Томашева Е.В., Кулеш И.В., Цветницкая Э.В.
Дата:
28.12.2015 12:22
В пособие излагается материал по аналитической химии в объеме соответствующих программ по специальностям: «Ветеринарная медицина», «Аграномия», «Биотехналогия». Содержатся методические указания по технике выполнения лабораторных работ по качественному и количественному анализу.
Содержатся методические указания по технике выполнения лабораторных работ по качественному и количественному анализу.
Скачать
Комментарии для работы с рабочими тетрадями по химии элементов
Размер файла:
655.75 kB
Дата:
28.12.2015 12:22
Комментарии для работы с рабочими тетрадями по химии элементов / З.В. Апанович, Ю.А. Лукашенко.
Учебно-методическое пособие включает лекции по отдельным темам курса «Неорганическая химия» и предназначено для контролируемой самостоятельной работы студентов инженерно – технологического факультета, для которых введен отдельный курс по химии элементов, а также может быть использовано студентами других факультетов.
Скачать
Практикум по физической химии
Размер файла:
1.03 MB
Дата:
01.04.2013 04:24
Учебно-методическое пособие (для проведения лабораторных занятий) для студентов инженерно-технического факультета
Практикум по физической химии: учеб.-мет. пособие / О. И. Валентюкевич.- Гродно: ГГАУ, 2008 – 88с.
Валентюкевич.- Гродно: ГГАУ, 2008 – 88с.
Данное пособие предназначено для студентов технологических специальностей аграрного университета. Целью данного пособия является оказание помощи в изучении теоретического материала, а также выработка навыков экспериментальной работы.
Скачать
Коллоидная химия
Размер файла:
834.37 kB
Дата:
01.04.2013 04:09
Учебно-методическое пособие (для проведения лабораторных занятий) для студентов инженерно-технического факультета
К-60 Практикум по физической химии: учеб.-мет. пособие / И. В. Кулеш, О. И. Валентюкевич.- Гродно: ГГАУ, 2013 – 94с.
Данное пособие предназначено для студентов технологических специальностей аграрного университета. Целью данного пособия является оказание помощи в изучении теоретического материала, а также выработка навыков экспериментальной работы.
Скачать
Курс лекций по дисциплине «Неорганическая химия»
Размер файла:
1.33 MB
Дата:
28.12.2015 12:22
Лекции по курсу «Неорганическая химия »для студентов инженерно – технологического факультета / З. В. Апанович.
В. Апанович.
Скачать
Рабочая тетрадь и методические указания по неорганической химии
Размер файла:
701.32 kB
Дата:
28.12.2015 12:23
Рабочая тетрадь и методические указания по неорганической химии. Для студентов технологических специальностей / З.В. Апанович.
Скачать
Ионные равновесия и обменные реакции в растворах электролитов
Скачать
Лабораторные работы по химии элементов для студентов технологических специальностей
Скачать
Университет
Error
Sorry, the requested file could not be found
More information about this error
Jump to…
Jump to…Новостной форумВстречи с АТб-18А2Встреча с АВСб-18Z1,2Лекции по дисциплинеhttps://meet.google.com/art-hjtd-cgjМатериалы по дисциплинеЗадание №1Ответы на задание №1 (Внешние световые приборы)Задание №2Ответы на задание №2 (рулевое управление)Задание №3Ответы на задание №3 (Определение токсичности отработавших газов)Задание №4Ответы на задание №4 (Определение шумности выхлопа)Итоговый тест по дисциплинеВстреча с АВСб-18Z 16. 03.2022Ссылка на встречи АТб-17А2МУ Диагн сист впрыскаВопросы к экзам по СИСТ ПИТ и УПРМУ по выполнению контрольной работыСписок АВСб18Z1Список АВСб18Z2Выполненная КРПракт №1 ОСПУАД (Бенз)Ответы на задание №1Практ №2 ОСПУАД (Диз)Ответы на задание №2Практ №3 ОСПУАД (Газ)Ответы на задание №3Итоговый тест по дисциплинеЗадание №1Отправка задания «Практика АТб-19″Материалы по практикеЗадание №2 до 20.04.20Ответы на задание №2Задание №3 до 04.05.20Ответы на задание №3Задание №4Ответы на задание №4Расписание занятий АТб-19А1Задание для отчета по учебной практике 1 курсОтчеты по практикеРАсписание на летнюю (соср) уч практикуВласов Тех обсл и ремонт а/мЗадание на уч. практику 2 (Летняя)Отчеты по учебной практике 2 (Летняя)Задание для отчёта по прктике АТб-19А1Материалы по практикеОтчеты по учебной практике №3Задание по практике№1Отправка задания «Практика АТб-18″Ответы на задание №2Задание №2 до 16.04.20Материалы по практикеЗадание №3 до 30.04.20Ответы на задание №3Задание №4 до 14.05.20Ответы на задание №4Расписание занятий АТб18А1Расписание занятий АТб18А2Задание №5 до 29.
03.2022Ссылка на встречи АТб-17А2МУ Диагн сист впрыскаВопросы к экзам по СИСТ ПИТ и УПРМУ по выполнению контрольной работыСписок АВСб18Z1Список АВСб18Z2Выполненная КРПракт №1 ОСПУАД (Бенз)Ответы на задание №1Практ №2 ОСПУАД (Диз)Ответы на задание №2Практ №3 ОСПУАД (Газ)Ответы на задание №3Итоговый тест по дисциплинеЗадание №1Отправка задания «Практика АТб-19″Материалы по практикеЗадание №2 до 20.04.20Ответы на задание №2Задание №3 до 04.05.20Ответы на задание №3Задание №4Ответы на задание №4Расписание занятий АТб-19А1Задание для отчета по учебной практике 1 курсОтчеты по практикеРАсписание на летнюю (соср) уч практикуВласов Тех обсл и ремонт а/мЗадание на уч. практику 2 (Летняя)Отчеты по учебной практике 2 (Летняя)Задание для отчёта по прктике АТб-19А1Материалы по практикеОтчеты по учебной практике №3Задание по практике№1Отправка задания «Практика АТб-18″Ответы на задание №2Задание №2 до 16.04.20Материалы по практикеЗадание №3 до 30.04.20Ответы на задание №3Задание №4 до 14.05.20Ответы на задание №4Расписание занятий АТб18А1Расписание занятий АТб18А2Задание №5 до 29. 05.20Ответы на задание №5Задание для отчёта по прктике АТб-18А1Задание для отчёта по прктике АТб-18А2Отчёты по практикеЗадание АТб-17А2Отправка задания «СТВДА»Задание СТВДА по теме №3 до 15.04.20Ответы на задание по теме №3Расписание занятий АТб17А2Задание СТВДА по теме №4 на 29.04.20Ответы на задание по теме №4Задание СТВДА по теме №5 на 13.05.20Ответы на задание по теме №5Лекции и материалы ЭиЭОАЗадание №1Задание №2Задание №3Вопросы к экз по ЭиЭОАИтоговый тестВстреча с АТб-19А1 15.11.21Лекция — Неисправности стартеровЛекции и материалы ЭиЭСАЗадание №1Задание №1Отправка вопросов по ЭОАЗадание №2Задание №2Задание №3Задание №3Задание №4Задание №4Вопросы к экз по ЭиЭСАИтоговый тестВстреча с АТб-18Z1,2 16.03.2022 в 17:05Диагностирование системы впрыска топлива с электронным управлением: Методические указания по выполнению лабораторной работыУстройство, функционирование и диагностирование электронной системы управления бензинового двигателя. Учебное пособиеЯковлев В.Ф. Диагностика электронных систем автомобиля.
05.20Ответы на задание №5Задание для отчёта по прктике АТб-18А1Задание для отчёта по прктике АТб-18А2Отчёты по практикеЗадание АТб-17А2Отправка задания «СТВДА»Задание СТВДА по теме №3 до 15.04.20Ответы на задание по теме №3Расписание занятий АТб17А2Задание СТВДА по теме №4 на 29.04.20Ответы на задание по теме №4Задание СТВДА по теме №5 на 13.05.20Ответы на задание по теме №5Лекции и материалы ЭиЭОАЗадание №1Задание №2Задание №3Вопросы к экз по ЭиЭОАИтоговый тестВстреча с АТб-19А1 15.11.21Лекция — Неисправности стартеровЛекции и материалы ЭиЭСАЗадание №1Задание №1Отправка вопросов по ЭОАЗадание №2Задание №2Задание №3Задание №3Задание №4Задание №4Вопросы к экз по ЭиЭСАИтоговый тестВстреча с АТб-18Z1,2 16.03.2022 в 17:05Диагностирование системы впрыска топлива с электронным управлением: Методические указания по выполнению лабораторной работыУстройство, функционирование и диагностирование электронной системы управления бензинового двигателя. Учебное пособиеЯковлев В.Ф. Диагностика электронных систем автомобиля. Учебное пособие (2003)Лекция 1. Общие сведения об электронных системах управления двигателемЛекция 2. Датчики электронных систем управления двигателемЛекция 3. Исполнительные элементы системы управления бензинового двигателяИсполнительные элементы системы управления бензинового двигателя. Часть 1Исполнительные элементы системы управления бензинового двигателя. Часть 2Исполнительные элементы системы управления бензинового двигателя. Часть 3Практическое занятие 1. Исследование характеристик датчиков электронной системы управления ДВСПрактическое занятие 2. Исследование функционирования электронной системы управления ДВСПрактическое занятие 3. Исследование влияния неисправностей элементов электронной системы управления ДВСЛабораторная работа №1Лабораторная работа №2Лабораторная работа №3Лабораторная работа №4Лабораторная работа №5Лабораторная работа №6Лабораторная работа №7Лабораторная работа №8Отправка лабораторных работВопросы к зачету по дисциплинеЗадание для контрольной работыОтправка контрольной работыПерезачет по дисциплинеСписок АТб18Z1Список АТб18Z2Итоговый тест по дисциплинеМатериалы по дисциплинеКР Сист упрОтправка КР по ДЭСАВопросы к зачету по дисциплине ДЭСАЗадание для АТб-17Z1-3Ссылка на встречи в период сессии (с 17.
Учебное пособие (2003)Лекция 1. Общие сведения об электронных системах управления двигателемЛекция 2. Датчики электронных систем управления двигателемЛекция 3. Исполнительные элементы системы управления бензинового двигателяИсполнительные элементы системы управления бензинового двигателя. Часть 1Исполнительные элементы системы управления бензинового двигателя. Часть 2Исполнительные элементы системы управления бензинового двигателя. Часть 3Практическое занятие 1. Исследование характеристик датчиков электронной системы управления ДВСПрактическое занятие 2. Исследование функционирования электронной системы управления ДВСПрактическое занятие 3. Исследование влияния неисправностей элементов электронной системы управления ДВСЛабораторная работа №1Лабораторная работа №2Лабораторная работа №3Лабораторная работа №4Лабораторная работа №5Лабораторная работа №6Лабораторная работа №7Лабораторная работа №8Отправка лабораторных работВопросы к зачету по дисциплинеЗадание для контрольной работыОтправка контрольной работыПерезачет по дисциплинеСписок АТб18Z1Список АТб18Z2Итоговый тест по дисциплинеМатериалы по дисциплинеКР Сист упрОтправка КР по ДЭСАВопросы к зачету по дисциплине ДЭСАЗадание для АТб-17Z1-3Ссылка на встречи в период сессии (с 17. 03.21)Задание на практ работу №1Выполненные задания по практической работе №1Задание на практ работу №2Выполненные задания по практической работе №2Задание на лабор работуОтчеты по лабор работеИтоговый тест по дисциплинеДля АТб-17А2 https://meet.google.com/vzc-kyyj-rchОтправка задания для зачетаВопросы к зачету по дисциплине ЭСАЭлектронные и микропроцессорные системы автомобилейУчеб пособиеИтоговое тестирование по дисциплинеОтправка заданий для зачетаКадровое обеспечение системы автосервисаас предприятияВопросы для зачетаВстречи с ПОб-19ZЭлектронные и микропроцессорные системы автомобилейУчеб пособиеКР ДЭиЭСКонтрольная работаВопросы к зачету по дисциплине ДЭиЭСОтветы на вопросы по дисциплинеИтоговый тест по дисциплинеВстреча с ДВСб-19А1 Лекции по ЭиЭСУВопросы по дисциплине ЭиЭСУСИСТЕМЫ ЭЛЕКТРОСНАБЖЕНИЯ И ЗАЖИГАНИЯ АВТОМОБИЛЕЙ Методические указания к лабораторным работам-5Задание для заочВопросы к экз по ЭиЭСУДВстреча с ДВСб-18А1 17.09.21Материалы по дисциплинеЗадание для ДВСб-18А1 на 01.
03.21)Задание на практ работу №1Выполненные задания по практической работе №1Задание на практ работу №2Выполненные задания по практической работе №2Задание на лабор работуОтчеты по лабор работеИтоговый тест по дисциплинеДля АТб-17А2 https://meet.google.com/vzc-kyyj-rchОтправка задания для зачетаВопросы к зачету по дисциплине ЭСАЭлектронные и микропроцессорные системы автомобилейУчеб пособиеИтоговое тестирование по дисциплинеОтправка заданий для зачетаКадровое обеспечение системы автосервисаас предприятияВопросы для зачетаВстречи с ПОб-19ZЭлектронные и микропроцессорные системы автомобилейУчеб пособиеКР ДЭиЭСКонтрольная работаВопросы к зачету по дисциплине ДЭиЭСОтветы на вопросы по дисциплинеИтоговый тест по дисциплинеВстреча с ДВСб-19А1 Лекции по ЭиЭСУВопросы по дисциплине ЭиЭСУСИСТЕМЫ ЭЛЕКТРОСНАБЖЕНИЯ И ЗАЖИГАНИЯ АВТОМОБИЛЕЙ Методические указания к лабораторным работам-5Задание для заочВопросы к экз по ЭиЭСУДВстреча с ДВСб-18А1 17.09.21Материалы по дисциплинеЗадание для ДВСб-18А1 на 01. 11Ответы на задание ДВСб-18А1 на 01.11.21Задание для ДВСб-18А1 на 29.11Лекции ДВСб-19А1Техническая диагностика (Лекции)Контрольные тесты по дисциплинеВопр ТехнДиагн — ДВСбМетод указ для контрольной работыЗадание для ДВСб-19Z1ДВСб-19Z1ДВСб-19Z1Контрольная работаМетод указанияТесты остат знанийВопросы для зачетаЗадание для заочСистемы двигателей ЛекцииВстречи АВСб-19ZРекомендуемая литератураОбсуждение тем по дисциплинеТеоретический материалПрактическое задание №1Ответы на практическое №1Практическое задание №2Ответы на практическое №2Практическое задание №3Ответы на практическое №3Практическое задание №4Ответы на практическое №4Итоговый тест по дисциплинеВопросы итог Оценка кач и сертЛекции Оценка кач и сертифРекомендуемая литератураТеоретический материалОбсуждение тем по дисциплинеЗадание для заочОтветы на заданиеВажно!Ссылка на встречи ЭТКм-20МАZ1Литература по дисциплинеКР Совр элек сист автКонтрольная работаЗадание практ №1Задание практ №1Задание практ №2Задание практ №2Задание практ №3Задание практ №3Задание практ №4Задание практ №4Задание практ №5Задание практ №5Вопросы по дисциплине СЭСАОтветы на вопросы для зачетаИтоговый тест по дисциплинеПракт задание №1Практ задание №1Итоговый тест по дисциплинеЗадание АТб 20А1Отчеты по практикеДневники по практикеОтчеты по практикеДневники по практикеЗадание АТб 17 А2Приказ на практику Атб-18А1,2По дисциплинеТехническая диагностика (Лекции)Задание №1 для ДВС-19А1 на 06.
11Ответы на задание ДВСб-18А1 на 01.11.21Задание для ДВСб-18А1 на 29.11Лекции ДВСб-19А1Техническая диагностика (Лекции)Контрольные тесты по дисциплинеВопр ТехнДиагн — ДВСбМетод указ для контрольной работыЗадание для ДВСб-19Z1ДВСб-19Z1ДВСб-19Z1Контрольная работаМетод указанияТесты остат знанийВопросы для зачетаЗадание для заочСистемы двигателей ЛекцииВстречи АВСб-19ZРекомендуемая литератураОбсуждение тем по дисциплинеТеоретический материалПрактическое задание №1Ответы на практическое №1Практическое задание №2Ответы на практическое №2Практическое задание №3Ответы на практическое №3Практическое задание №4Ответы на практическое №4Итоговый тест по дисциплинеВопросы итог Оценка кач и сертЛекции Оценка кач и сертифРекомендуемая литератураТеоретический материалОбсуждение тем по дисциплинеЗадание для заочОтветы на заданиеВажно!Ссылка на встречи ЭТКм-20МАZ1Литература по дисциплинеКР Совр элек сист автКонтрольная работаЗадание практ №1Задание практ №1Задание практ №2Задание практ №2Задание практ №3Задание практ №3Задание практ №4Задание практ №4Задание практ №5Задание практ №5Вопросы по дисциплине СЭСАОтветы на вопросы для зачетаИтоговый тест по дисциплинеПракт задание №1Практ задание №1Итоговый тест по дисциплинеЗадание АТб 20А1Отчеты по практикеДневники по практикеОтчеты по практикеДневники по практикеЗадание АТб 17 А2Приказ на практику Атб-18А1,2По дисциплинеТехническая диагностика (Лекции)Задание №1 для ДВС-19А1 на 06. 11.21Задание №1 для ДВСб-19А1 на 06.11.21Контрольные тесты по дисциплинеВопр ТехнДиагн — ДВСбБилеты Теор Диаг ДВСбМУ. Опред осн хар диаг парРасписание занятий ДВСб-18А1Практ зан №2Ответы на Задание №2Практ зан №3Ответы на задание №3Практ зан №4Ответы на задание №4Лабораторная работа №1Лабораторная работа №2Лабораторная работа №3Лабораторная работа №4Итоговый тест по дисциплинеДля АТб-18 А2 https://meet.google.com/srz-xyjq-fncТеоретические материалыВопросы по дисциплинеРасписание АТб18А2Практическое задание №1Практич задание №1Практическое задание №2Практическое задание №2Практическое задание №3Практическое задание №3Практическое задание «Алгоритм общения с клиентом»Лекционный материалМатериалы по семестровому заданиюЗадание для заочниковОтветы на задание для заочниковВопросы для экзаменаСсылка на встречуСсылка на занятия с АВСб-20ZРаздел 1. Основы организации сервисных услуг по техническому обслуживанию и ремонту автомототранспортных средствРаздел 2. Производственная инфраструктура предприятияРаздел 3.
11.21Задание №1 для ДВСб-19А1 на 06.11.21Контрольные тесты по дисциплинеВопр ТехнДиагн — ДВСбБилеты Теор Диаг ДВСбМУ. Опред осн хар диаг парРасписание занятий ДВСб-18А1Практ зан №2Ответы на Задание №2Практ зан №3Ответы на задание №3Практ зан №4Ответы на задание №4Лабораторная работа №1Лабораторная работа №2Лабораторная работа №3Лабораторная работа №4Итоговый тест по дисциплинеДля АТб-18 А2 https://meet.google.com/srz-xyjq-fncТеоретические материалыВопросы по дисциплинеРасписание АТб18А2Практическое задание №1Практич задание №1Практическое задание №2Практическое задание №2Практическое задание №3Практическое задание №3Практическое задание «Алгоритм общения с клиентом»Лекционный материалМатериалы по семестровому заданиюЗадание для заочниковОтветы на задание для заочниковВопросы для экзаменаСсылка на встречуСсылка на занятия с АВСб-20ZРаздел 1. Основы организации сервисных услуг по техническому обслуживанию и ремонту автомототранспортных средствРаздел 2. Производственная инфраструктура предприятияРаздел 3. Бизнес-планирование предприятий автомобильного сервисаРаздел 4. Организация работы с потребителемРаздел 5. Организация и нормирование труда в автосервисном предприятииТеоретические материалыПрактическая работа 1 АВСб-20ZПрактическая работа 1 АВСб-20ZПрактическая работа 2 АВСб-20ZПрактическая работа 2 АВСб-20ZПрактическая работа 3 АВСб-20ZПрактическая работа 3 АВСб-20ZЗадание для АТб-20А2 на 01-06.11.21Задание по лекциям на 01-06.11.21 АТб-20А2Задание по практическим на 01-06.11.21 для АТб-20А2Тесты ООФАСВсё для экзаменаОтветы на вопросы экзаменаПрактическая работа №1 (АТб-20А2)Практическая работа №2Итоговый тестСсылка на встречу в Google MeetНСб-21Т1 Задание для отчета по учебной практике 1 курсАТб-21А Задание для отчета по учебной практике 1 курсОтчеты по практике АТб-21А (Задание №1)Отчеты по практике НСб-21Т (Задание №1)Титульный образецСписок использованных источников. Правила оформленияЗадание для заочного ф-таМатериалы по дисциплинеВидеоматериалы по дисциплинеЗадание №1Задание №2Видеовстречи ДВСбИтоговый тест по дисциплинеМатериалы по дисциплинеЗадание к лабораторнойЗадание к лабораторнойЗадание на практ работу №1Практическое задание №1Задание на практ работу №2Практическая работа№2Опрос 1 Контр.
Бизнес-планирование предприятий автомобильного сервисаРаздел 4. Организация работы с потребителемРаздел 5. Организация и нормирование труда в автосервисном предприятииТеоретические материалыПрактическая работа 1 АВСб-20ZПрактическая работа 1 АВСб-20ZПрактическая работа 2 АВСб-20ZПрактическая работа 2 АВСб-20ZПрактическая работа 3 АВСб-20ZПрактическая работа 3 АВСб-20ZЗадание для АТб-20А2 на 01-06.11.21Задание по лекциям на 01-06.11.21 АТб-20А2Задание по практическим на 01-06.11.21 для АТб-20А2Тесты ООФАСВсё для экзаменаОтветы на вопросы экзаменаПрактическая работа №1 (АТб-20А2)Практическая работа №2Итоговый тестСсылка на встречу в Google MeetНСб-21Т1 Задание для отчета по учебной практике 1 курсАТб-21А Задание для отчета по учебной практике 1 курсОтчеты по практике АТб-21А (Задание №1)Отчеты по практике НСб-21Т (Задание №1)Титульный образецСписок использованных источников. Правила оформленияЗадание для заочного ф-таМатериалы по дисциплинеВидеоматериалы по дисциплинеЗадание №1Задание №2Видеовстречи ДВСбИтоговый тест по дисциплинеМатериалы по дисциплинеЗадание к лабораторнойЗадание к лабораторнойЗадание на практ работу №1Практическое задание №1Задание на практ работу №2Практическая работа№2Опрос 1 Контр. неделяВопросы к зачету по дисциплине ЭСУДСписок рек литературыНорм-прав регул в АТЭТеоретические материалыЛабораторные работыОтчеты по лабор рабВстречи с АВСб-19ZИтоговый тест по дисциплинеПрактическое задание (Технологическая карта) ДВСб-19А1Внимание! Наша кафедра теперь называется «Автомобильный транспорт»Задание произв практика (по получ)Приказ на практику АВСб-18ZОтчеты по практикеДневники по практике
неделяВопросы к зачету по дисциплине ЭСУДСписок рек литературыНорм-прав регул в АТЭТеоретические материалыЛабораторные работыОтчеты по лабор рабВстречи с АВСб-19ZИтоговый тест по дисциплинеПрактическое задание (Технологическая карта) ДВСб-19А1Внимание! Наша кафедра теперь называется «Автомобильный транспорт»Задание произв практика (по получ)Приказ на практику АВСб-18ZОтчеты по практикеДневники по практике
Skip Statistics
404 Not Found
Главная > Ошибка 404
-Выпускникам и работодателям
-Инновации
Международная деятельность
Управление международной деятельностиНовости и события международной деятельностиМеждународное партнерствоМеждународные проектыОбучение и научная работа за рубежомОбъявления Обучение и научная работа иностранных граждан в ИРНИТУОфис преподавателя DAAD в ИРНИТУ Задать вопрос
-Программа НИУ
-Об университете
Образование
Уровни образованияИнституты и факультеты
-Общественная жизнь
Пресс-служба
Университет в СМИ
-Сотрудникам и преподавателям
-Студентам
Настройки задать вопрос
Языковой набор
Диссертации
Фото
АрхитекторыДизайн218МузеиФотогалереи (Дашко)
Персоны
Сторонние персоныКоманда по хоккеюСтуденты
Структура
РекторатУченый советУчебные подразделенияАдминистративные подразделенияОбщественные объединенияНаучная деятельностьДиректора институтов
ИРНИТУ
Об ИРНИТУДеятельностьПоступлениеСтудентуШкольникуСотрудникуВыпускнику и работодателюСведения об образовательной организацииАдминистрированиеРекторОбращения гражданТОП 100Версия для слабовидящихРазноеКонтактыРасписаниеПорядок приемаДля тестов
Записи
Информация о представительствах КитайНазваниеИнформация об учредителе (учредителях) образовательной организацииФинансово- хозяйственная деятельностьИнформация о филиале образовательной организацииИнформация о порядке оказания платных образовательных услугСтипендии и меры поддержки обучающихся Руководитель филиала образовательной организацииВакантные места для приема (перевода) обучающихся Направления и результаты научной (научно-исследовательской) деятельностиРуководство. Педагогический (научно-педагогический) составИнформационне системы и информационно-телекоммуникационные сетиМатериально-технические условия, обеспечивающие возможность беспрепятственного доступа поступающих с ограниченными возможностями здоровьяФГОСИнформация об образовательной организацииПорядок приемаИнформация о представительствах
Педагогический (научно-педагогический) составИнформационне системы и информационно-телекоммуникационные сетиМатериально-технические условия, обеспечивающие возможность беспрепятственного доступа поступающих с ограниченными возможностями здоровьяФГОСИнформация об образовательной организацииПорядок приемаИнформация о представительствах
Типы структур
Научные специальности
Математика и механикаФизика и астрономияХимические наукиНауки о землеБиологические наукиАрхитектураТехника и технологии строительстваИнформатика и вычислительная техникаЭлектроника, радиотехника и системы связиЭлектро- и теплотехникаЯдерная, тепловая и возобновляемая энергетика и сопутствующие технологииМашиностроениеХимическая технологияПромышленная экология и биотехнологииТехносферная безопасностьГеология, разведка и разработка полезных ископаемыхТехнологии материаловТехника и технологии наземного транспортаАвиационная и ракетно-космическая техникаУправление в технических системахСоциологические наукиЮриспруденцияЯзыкознание и литературоведениеИсторические науки и археологияФизическая культура и спортИскусствоведениеОхрана окружающей среды. Экология человекаКультурологияЭкономика
Экология человекаКультурологияЭкономика
Справочник направлений
Телефонный справочник
РекторатАдминистративные подразделенияУчебные подразделенияОбщественные объединения
Помещения/аудитории
ТОМСул.Игошина, 7ул. 4-я Железнодорожная, 104Общежитие 5ул. Ивана Франко,28ул. Карла Либкнехта,153Общежитие 7 (ул.Игошина, 6)г. Усолье-Сибирское, проспект Комсомольский, 65Актовый залул. Лермонтова, 81/18ул. Лермонтова 81/21ул. 4-ая Железнодорожная, 189Общежитие 12а (ул. Игошина, 1)Общежитие 9Общежитие 10Общежитие 11Общежитие 12бОбщежитие 12вОбщежитие 12гОбщежитие 13аОбщежитие 13бОбщежитие 14Общежитие 15Общежитие 16Общежитие 16а (ул. Лермонтова, 102а)Общежитие 11аОбщежитие 1ул. Академика Курчатова, 3Общежитие 3 (ул. Лермонтова, 89)Корпус БИ БРИКС (ул. Лермонтова 83а)Главный корпусТехнопарк ( ул. Игошина 1А)г. Усолье — Сибирское, ул. Менделеева, 65ул. 4-ая Железнодорожная, 159 ул. Игошина,4 ул. Лермонтова, д. 130 ул. Баррикад, 147Музей боевой славыул. Лермонтова, 104ул. Игошина, 8 приход пр. Сергея РадонежскогоОбщежитие 8 (ул. Академика Курчатова, 14)ул. Советская, 55ул. Фаворского 1А
Игошина,4 ул. Лермонтова, д. 130 ул. Баррикад, 147Музей боевой славыул. Лермонтова, 104ул. Игошина, 8 приход пр. Сергея РадонежскогоОбщежитие 8 (ул. Академика Курчатова, 14)ул. Советская, 55ул. Фаворского 1А
Оборудование
НИЛ радиофизикиНИЛ «Прикладная химия и биотехнология» НИЛ плазменной радиофизикиНИЛ лазерной физики НИЛ мониторинга физического здоровьяНИЛ рентгеноструктурного анализа НИЛ физических свойств микро- и наноструктурНИЛ исследований и анализа нефти и нефтепродуктов»НИЛ комплексных инженерных изысканий НИЛ геммологииНИЛ исследования технологических остаточных напряжений и деформацийНИЛ качества водыНИЛ технологии высокопроизводительной механообработки, формообразования и упрочнения деталей машинНИЛ режимов работы электроэнергетических систем НИЛ систем измерения и АСУТП Центр коллективного пользования «Байкальский центр нанотехнологий»НИЛ геомеханики и физики горных породНИЛ техники высоких напряжений НИЛ промышленной и пожарной безопасностиНИЛ катализа и органического синтеза НИЛ археологии, палеоэкологии и систем жизнедеятельности народов Северной АзииНИЛ экологического мониторинга природных и техногенных средНИЛ совершенствования строительных процессов и контроля качества Центр коллективного пользования «Техносферная безопасность»НИЛ «Электротехнологии»НИЛ Центр маркшейдерско-геодезических инновацийНИЛ современных нагревательных приборовНИЛ диагностики электрооборудованияНИЛ высокоточной сборки и монтажа конструкций и сооруженийНИЛ «Физико-химические исследования металлургических процессов»НИЛ исследования энергоэффективности зданий, инженерных систем и сооружений НИЛ обработки, ремонта и диагностики композиционных материаловНИЛ «Прогрессивные методы формообразования и отделочно-упрочняющей обработки в механосборочном производстве»НИЛ роботизированных технологий в авиастроенииНИЛ технической диагностикиНИЛ «Технология финишной обработки»НИЛ зондовой микроскопииНИЛ инженерной экологииНИЛ «Исследовательский комплекс новых строительных технологий и материалов» НИЛ по прогрессивным методам формообразования в заготовительно-штамповочном производстве НИЛ проектирования и виртуального моделирования изделий и технологических процессов в авиастроении» НИЛ электронной микроскопии №1 НИЛ «Технологии углеродных материалов» Научно-исследовательская транспортная лаборатория ИРНИТУНИЛ прикладной геохимии и аналитических методов исследованияНИЛ испытания строительных материалов и конструкцийНИЛ автоматизированного минералогического анализаНИЛ анализа кремниевых структурНИЛ геологической информатики
Позиционирование
Направления и специальности
СПОАспирантураБакалавриатМагистратураСпециалитетСоциальные науки
Экзамены
МагистратураАспирантура
Ступени обучения
Форма обучения
Документы
РекторатРУСАЛИРКУТДля министерского сайтаРежим и безопасностьНаукаИнститутыЭкологическая политикаВыпускнику и работодателюИнклюзивное образованиеОб ИРНИТУ Первичная профсоюзная организация работников ИРНИТУОбразованиеМеждународная деятельностьДокументы для скачиванияАбитуриентуФакультет среднего профессионального образованияВоспитание, культура, спорт, здоровьеПриоритет 2030Отдел ГО и ЧСИздательствоСведения об образовательной организацииКомиссииДля тестовОтдел мониторинга и качества образовательных услугФакультет физической культуры и спортаОтдел лицензирования и аккредитации образовательных программОбщие документыУчебный отделПресс-службаФилиал ФГБОУ ВО ИРНИТУ в г. Усолье-СибирскомИнновацииСтудентуИнформатизацияСотрудникуУчебные подразделенияАдминистративные подразделенияПоложения о подразделениях
Усолье-СибирскомИнновацииСтудентуИнформатизацияСотрудникуУчебные подразделенияАдминистративные подразделенияПоложения о подразделениях
Типы документов
Подборки документов
Об ИРНИТУРежим и безопасностьИнклюзивное образованиеДля министерского сайтаСтудентуАбитуриентуИнститутыОбразованиеМеждународная деятельностьФакультет среднего профессионального образованияСведения об образовательной организацииПриоритет 2030Экологическая политикаУчебный отделИздательствоКомиссииУченый советВоспитание, культура, спорт, здоровьеОтдел мониторинга и качества образовательных услугФакультет физической культуры и спортаПресс-службаОтдел лицензирования и аккредитации образовательных программЗакупкиИнновацииНаукаАдминистративные подразделения
Шаблон плана аварийного восстановления
Шаблон плана аварийного восстановления
Две компании, в которых я работал, пережили катастрофу, когда я отвечал за их планы аварийного восстановления. Один из них в восьмидесятых был сожжен поджигателем, и мне, как ИТ-менеджеру, нужно было все восстановить и запустить – и я рад сообщить, что мне это удалось, причем успешно. Второй была компания, чья штаб-квартира опиралась на Бансфилд, и я отвечал за вспомогательный офис, на который это косвенно повлияло. В обоих случаях план аварийного восстановления был просто незаменим.
Один из них в восьмидесятых был сожжен поджигателем, и мне, как ИТ-менеджеру, нужно было все восстановить и запустить – и я рад сообщить, что мне это удалось, причем успешно. Второй была компания, чья штаб-квартира опиралась на Бансфилд, и я отвечал за вспомогательный офис, на который это косвенно повлияло. В обоих случаях план аварийного восстановления был просто незаменим.
Катастрофы случаются чаще, чем вы думаете: наводнения, пожары, утечки газа, наезды транспортных средств на здания, саботаж и так далее. Запланируйте это, и вы поправитесь гораздо легче, чем если бы вы этого не сделали. Пожалуйста, не стесняйтесь использовать эту статью в качестве отправной точки.
Прежде всего, потому что они часто путаются, пожалуйста, уделите немного времени, чтобы понять разницу между непрерывностью бизнеса и аварийным восстановлением, поскольку вас могут попросить о первом, когда требуется второе.
Непрерывность бизнеса сохраняет функционирование бизнеса и Обычно часто включает в себя использование ручных альтернатив в компьютеризированные системы (когда оно напрямую затронут событие). Это срабатывает сразу после объявления катастрофы. Для ИТ это гарантирует, что служба поддержки будет продолжать принимать звонки, инструкторы будут продолжать обучение, а устройства конечных пользователей будут продолжать развертываться и ремонтироваться и т. д.
Это срабатывает сразу после объявления катастрофы. Для ИТ это гарантирует, что служба поддержки будет продолжать принимать звонки, инструкторы будут продолжать обучение, а устройства конечных пользователей будут продолжать развертываться и ремонтироваться и т. д.
Аварийное восстановление позволяет восстанавливать инфраструктуру и системы после аварии. Хотя это является срочным делом, оно имеет тенденцию постепенно нарастать по мере завершения расследований и достижения соглашения о том, как и когда будет достигнуто восстановление. Аварийное восстановление гарантирует, что нефункционирующие системы снова заработают, данные будут восстановлены, а среда вернется в устойчивое состояние.
Неисправность может быть вызвана многими причинами, но в этом документе она рассматривается в соответствии с одной из трех классификаций: сбой оборудования, недоступность системы или потеря среды. В некоторых случаях может потребоваться подход «Mix’n’Match», и руководство, содержащееся в этом документе, не следует рассматривать как ограничивающее.
Достаточно преамбулы, вот шаблон:
Шаблон плана аварийного восстановления ИТ
На титульном листе документа укажите, кто несет ответственность, подотчетен, какую область он охватывает (например, ИТ), кто его утвердил (например, руководитель ИТ), статус (черновик, одобрено и т. д.), дату выпуска, дату следующей проверки, название документа (например, план аварийного восстановления для ИТ 01012020.DOCX) и список рассылки (по ролям и имя)
Теперь добавьте следующие разделы, при необходимости адаптировав предлагаемый текст:
Определения
Непрерывность бизнеса (BC): Деятельность, обеспечивающая продолжение работы бизнес-функций сразу после аварии, часто включает возврат к бумажным системам в случае сбоя ИТ.
План обеспечения непрерывности бизнеса (BCP): План внедрения процессов обеспечения непрерывности бизнеса в случае аварии.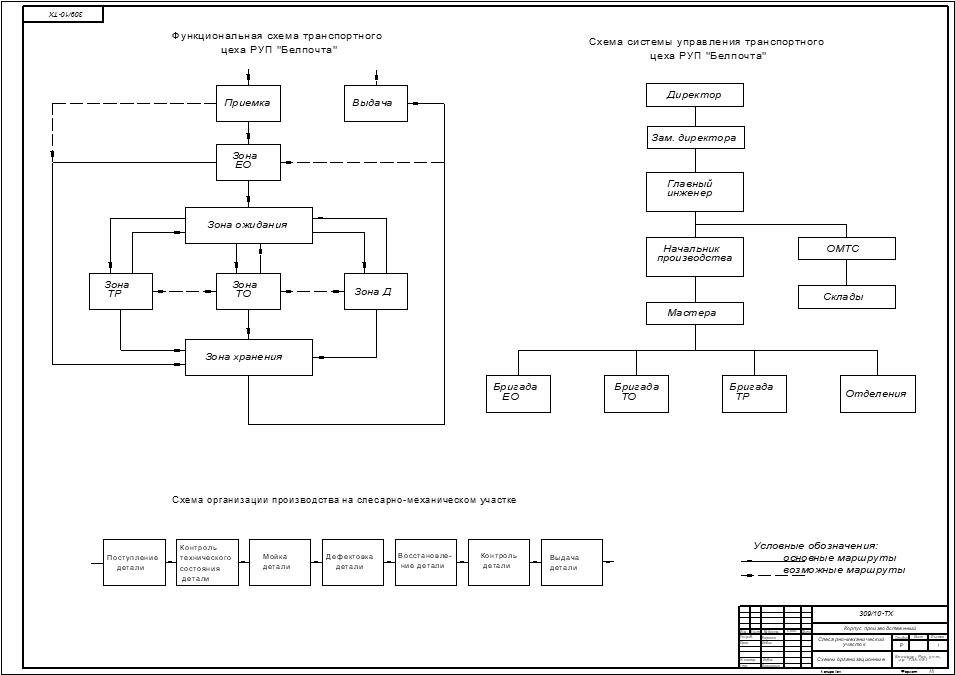
Облако / Облачные вычисления : Хранение и обработка данных по запросу через центр обработки данных, доступ к которому осуществляется через Интернет.
Катастрофа: Любое событие, вызывающее значительный и длительный перерыв в предоставлении ИТ-услуг организации
D isaster Recovery (DR): Деятельность по восстановлению данных и восстановлению предоставления ИТ-услуг
Аварийная ситуация Восстановление как услуга (DRaaS): Репликация и размещение физических и виртуальных серверов третьей стороной для обеспечения аварийного переключения и восстановления после отказа в случае аварии
План аварийного восстановления (DRP): План восстановления после аварии
Аварийное переключение и восстановление после отказа : Аварийное переключение — это когда система автоматически передает управление системе-дубликату при обнаружении сбоя или сбоя (например, при возникновении аварии). Failback — это когда он переносится обратно.
Failback — это когда он переносится обратно.
Группа аварийного восстановления ИТ-отдела: Группа ИТ-отдела, которая будет работать вместе над выполнением плана аварийного восстановления составные части процесса и как они взаимодействуют
Целевая точка восстановления (RPO): Максимальный период, в течение которого данные могут быть потеряны из ИТ-службы из-за аварии. NB: «Потерянный для ИТ-системы» не «полностью потерянный», так как бумажные альтернативы будут введены в действие как часть Плана обеспечения непрерывности бизнеса.
Целевое время восстановления (RTO) : Целевая продолжительность и уровень обслуживания, в течение которых бизнес-процесс должен быть восстановлен после аварии, чтобы избежать неприемлемых последствий.
Стабильное состояние : Живая среда, которая существует для ведения бизнеса до аварии, и целевая среда, к которой можно вернуться после.
Стратегическое командование: Персонал, принимающий решения о штатном расписании и приоритетах задач, стратегии разрешения проблем и общей координации усилий по восстановлению.
Тактическое командование: Персонал, предоставляющий необходимые решения. Это включает в себя оперативную деятельность (также известную как Operational Command 9).0006), так и тактические. У вас может быть отдельная оперативная группа , но это слишком бюрократично.
Введение
В этом документе представлены структурированные рекомендации по процессу восстановления после любой аварии, которая напрямую влияет на предоставление ИТ-услуг. Он предназначен для ускорения процесса восстановления путем предоставления точек действия, но, поскольку каждое бедствие отличается, он не может быть окончательным и должен будет разумно применяться Группой старшего руководства ИТ в каждой конкретной ситуации во взаимодействии с персоналом из пораженные участки.
Следует отметить, что наличие плана восстановления не является альтернативой профилактике. Конечно, гораздо лучше вообще избежать катастрофы, чем «хорошо оправиться» от нее. С этой целью старший ИТ-персонал должен регулярно оценивать риски и проблемы, связанные с предоставлением ИТ-услуг, и соответствующим образом корректировать этот документ.
С этой целью старший ИТ-персонал должен регулярно оценивать риски и проблемы, связанные с предоставлением ИТ-услуг, и соответствующим образом корректировать этот документ.
Цели
Основными целями этого документа являются:
- помощь ИТ-подразделению организации в восстановлении после аварии, обеспечивая плавное и быстрое восстановление обслуживания, не подвергая опасности персонал, пациентов или третьих лиц
- гарантировать, что организация сможет восстановить утерянную и поврежденную информацию после стихийного бедствия
- защитить конфиденциальную информацию от несанкционированного доступа, облегчив при этом надлежащий доступ, безопасно
- снизить стоимость восстановления после стихийного бедствия
- снизить риск возникновения стихийных бедствий при аналогичном событии в будущем
- координировать восстановление после аварии в рамках всей организации со всеми другими пострадавшими отделами
- определять и определять приоритетность критически важных услуг, предоставляемых службой ИТ-отдела
- описание того, как службы будут восстановлены в случае чрезвычайной ситуации
- определение основных контактных лиц ИТ-отдела во время чрезвычайной ситуации
- помощь персоналу, не связанному с ИТ, понимание действий, которые ИТ-персонал предпримет в случае аварии
Область применения
Документ охватывает все услуги по предоставлению ИТ-услуг организации, включая как внутренние, так и внешние (например, облачные). Он не распространяется на аварийное восстановление для инцидентов, не связанных с ИТ, и не распространяется на обеспечение непрерывности бизнеса. NB: вы должны очень четко указать, что, по вашему мнению, входит в состав «ИТ» и, следовательно, покрывается этим планом аварийного восстановления, например. Мобильные телефоны и т. д.
Он не распространяется на аварийное восстановление для инцидентов, не связанных с ИТ, и не распространяется на обеспечение непрерывности бизнеса. NB: вы должны очень четко указать, что, по вашему мнению, входит в состав «ИТ» и, следовательно, покрывается этим планом аварийного восстановления, например. Мобильные телефоны и т. д.
Стратегия восстановления (ответственность [Роли])
Стратегия восстановления заключается в использовании облачных вычислений для аварийного восстановления (вы можете быть более традиционным, но не забывайте о DRaaS!). Большинство ключевых систем размещаются за пределами площадки, а остальные покрываются аварийным восстановлением как услугой (DRaaS), если их экономически невозможно разместить в облаке. До тех пор, пока стратегия не будет полностью реализована, все системы, которые не размещены за пределами площадки, будут иметь удаленные иерархические резервные копии данных, которые будут восстановлены на соответствующих серверах или альтернативных компьютерах в пределах RPO, чтобы гарантировать, что никакие данные не будут потеряны. Эти резервные копии будут проверены на целостность путем проведения тестового восстановления не менее одной резервной копии в месяц. Текущий цикл пять недель — таким образом, системы могут быть восстановлены до точки пятью неделями ранее.
Эти резервные копии будут проверены на целостность путем проведения тестового восстановления не менее одной резервной копии в месяц. Текущий цикл пять недель — таким образом, системы могут быть восстановлены до точки пятью неделями ранее.
Резервные копии прикладного программного обеспечения хранятся за пределами предприятия, отражая установленные версии, и их также можно получить у поставщиков в экстренных случаях.
Подтверждение плана (ответственность [Роли])
План должен подвергаться кабинетному тестированию не реже одного раза в год, когда разыгрывается сценарий стихийного бедствия. Этот тест должен быть разработан для тщательной проверки плана. Оценка должна быть динамичной (т. е. первоначальный сценарий бедствия должен меняться с течением времени, и в ходе учений должна поступать новая информация). После этого следует провести совещание по извлечению уроков и соответствующим образом скорректировать план.
Роли и обязанности
Внутренний
Создайте здесь таблицу, чтобы показать отдельные роли и обязанности для действий по восстановлению, включая:
Городской, электронная почта.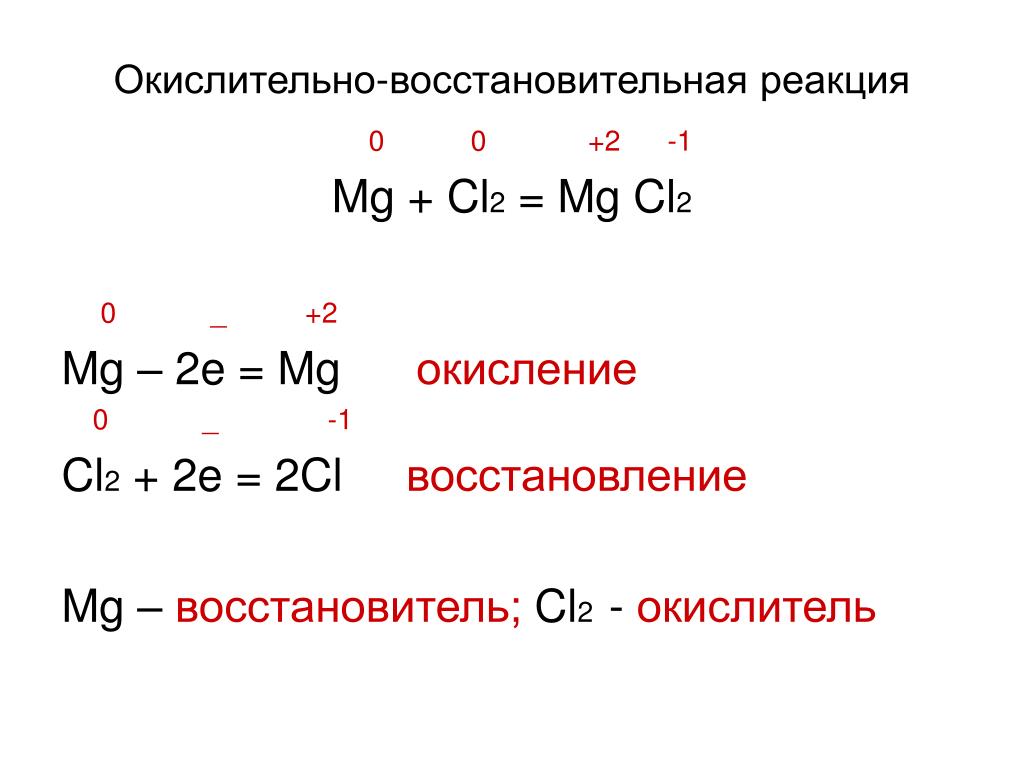 Вот некоторые примеры процесса/процедуры восстановления: ответственный за аварийное восстановление (RTO и RPO, заместитель по [роли], ответственный за тактическую координацию между ИТ, приложениями и системами, сторонней поддержкой и инфраструктурой, службой поддержки и выездными службами Подумайте немного об этом в начале, а также когда вы закончите остальную часть плана.0010
Вот некоторые примеры процесса/процедуры восстановления: ответственный за аварийное восстановление (RTO и RPO, заместитель по [роли], ответственный за тактическую координацию между ИТ, приложениями и системами, сторонней поддержкой и инфраструктурой, службой поддержки и выездными службами Подумайте немного об этом в начале, а также когда вы закончите остальную часть плана.0010
Одна из ролей, которая потребуется, — это роль менеджера по инцидентам. Если у вас уже есть менеджер по инцидентам, то он, очевидно, возьмет на себя эту роль. Если вы этого не сделаете, вам нужно будет назначить его на время аварийного восстановления.
Внешний
Список поставщиков в Приложении A содержит контакты поставщиков и поддерживается [Роль].
Восстановление после сбоя системы
В случае серьезного сбоя системы персонал организации должен будет провести расследование и при необходимости привлечь третьи стороны. Решение будет результатом объединения усилий обеих сторон, работающих как единая команда.
Процесс восстановления системы описан более подробно в следующих разделах с использованием блок-схемы процесса (PFD) и подробных описаний каждой задачи после PFD.
Приложения, поддерживаемые ИТ-отделом, перечислены в Приложении C.
Задокументируйте ПРОЦЕСС ВОССТАНОВЛЕНИЯ СИСТЕМЫ здесь: Я перечисляю ряд действий, которые вы можете рассмотреть, и их следует поместить в простой процесс Блок-схема (PFD). Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддаются соблазну использовать такие инструменты, как Visio, которые мешают легкому обновлению PFD в дальнейшем.
ПРОЦЕСС ВОССТАНОВЛЕНИЯ СИСТЕМЫ
0 Значительная потеря обслуживания :
Одна или несколько ключевых систем (приоритеты 1 и 2 в списке приложений в этом документе) недоступны.
1 Бедствие ?
MD/CEO информирует руководителя отдела информационных технологий о мероприятии. Управляющий директор/генеральный директор, руководитель ИТ-отдела и операционный директор решают, следует ли классифицировать это как стихийное бедствие.
Владелец/лицо, принимающее решения: управляющий директор/генеральный директор/руководитель отдела ИТ/операционный директор
2 Инициирован DRP :
План аварийного восстановления (DRP) официально отмечен как инициированный.
Владелец/лицо, принимающее решение: руководитель отдела ИТ
3 Краткий отчет менеджера по чрезвычайным ситуациям
Начальник отдела ИТ звонит менеджеру по инцидентам, чтобы сообщить им о ситуации и подтвердить необходимость активации DRP.
Владелец/лицо, принимающее решения: руководитель отдела ИТ
4 Убедитесь, что BCP инициированы :
Убедитесь, что все соответствующие планы обеспечения непрерывности бизнеса были активированы через процессы BCP. Они содержат ряд действий, дополняющих DRP и поэтому не дублирующихся в нем.
Они содержат ряд действий, дополняющих DRP и поэтому не дублирующихся в нем.
Владелец/лицо, принимающее решение: Менеджер по ликвидации чрезвычайных ситуаций
5 Доступ к папке DRP :
Всем ИТ-руководителям доступ к плану аварийного восстановления и мобилизация их команд по мере необходимости 6 Сообщите ИТ-специалисту SMT о том, что DRP был запущен :
Отправьте электронное письмо и мгновенное сообщение/текстовое сообщение группе аварийного восстановления ИТ (как указано в разделе « Роли и обязанности ») в этом документе.) Также позвоните руководителю IT для обсуждения ситуации и дальнейших действий.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
7 Проведение первоначального инструктажа группы аварийного восстановления:
Менеджер по инцидентам организует и проводит первоначальный инструктаж для группы аварийного восстановления ИТ, ознакомившись с проблемой совместно с руководителем отдела ИТ и персоналом земля.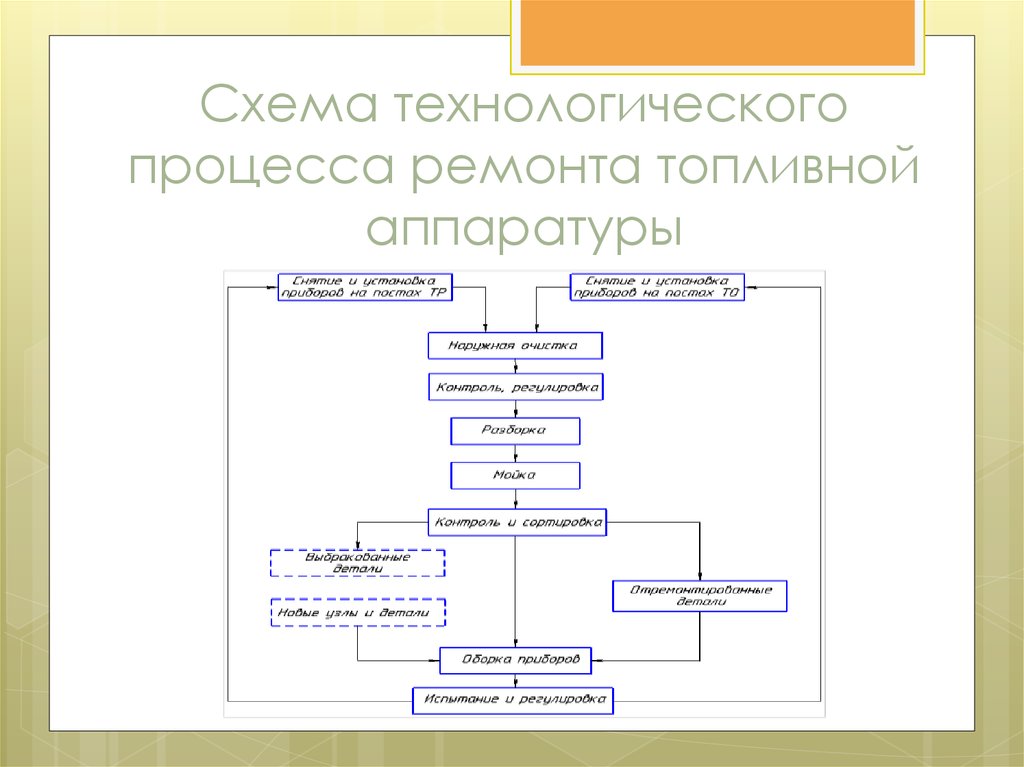
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
8 Первоначальный диагностик :
Официально изложите возникшую проблему и сделайте первоначальный диагноз относительно того, какова предполагаемая основная причина(ы) проблемы. Консультировать команду IT DR. Примите к сведению их взгляды и идеи.
Владелец/лицо, принимающее решения: Диспетчер инцидентов
9 3-я проблема? :
Группа аварийного восстановления ИТ для обсуждения ситуации и принятия решения о привлечении третьей стороны, а также о кратком изложении.
Список компаний DRaaS приведен в Приложении E.
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ (председатель: Руководитель ИТ)
10 Привлечение третьей стороны для выполнения работы выполнить работу, при необходимости подняв аварийный ЗП
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ
11 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе выполнения и обновить группу аварийного восстановления ИТ. Если позволяет время, создайте короткую информационную записку.
Если позволяет время, создайте короткую информационную записку.
Запись всех действий в журнал инцидентов.
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
12 Диагностика, планирование и исправление :
Команда аварийно-спасательных служб ИТ решает, кто поддерживает связь с третьей стороной (если задействована), кто что делает в команде и когда
NB: На этом шаге также требуется определение того, что будет означать «фиксированное». Это должно быть объективно. Также этот шаг является итеративным.
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ (председатель: Менеджер по ликвидации последствий)
13 Устранена неисправность:
Считает ли группа аварийного восстановления ИТ, что неисправность устранена и системы можно восстановить?
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ-отдела
14 Просмотр диагноза:
Просмотрите диагноз, чтобы убедиться, что это все еще считается проблемой.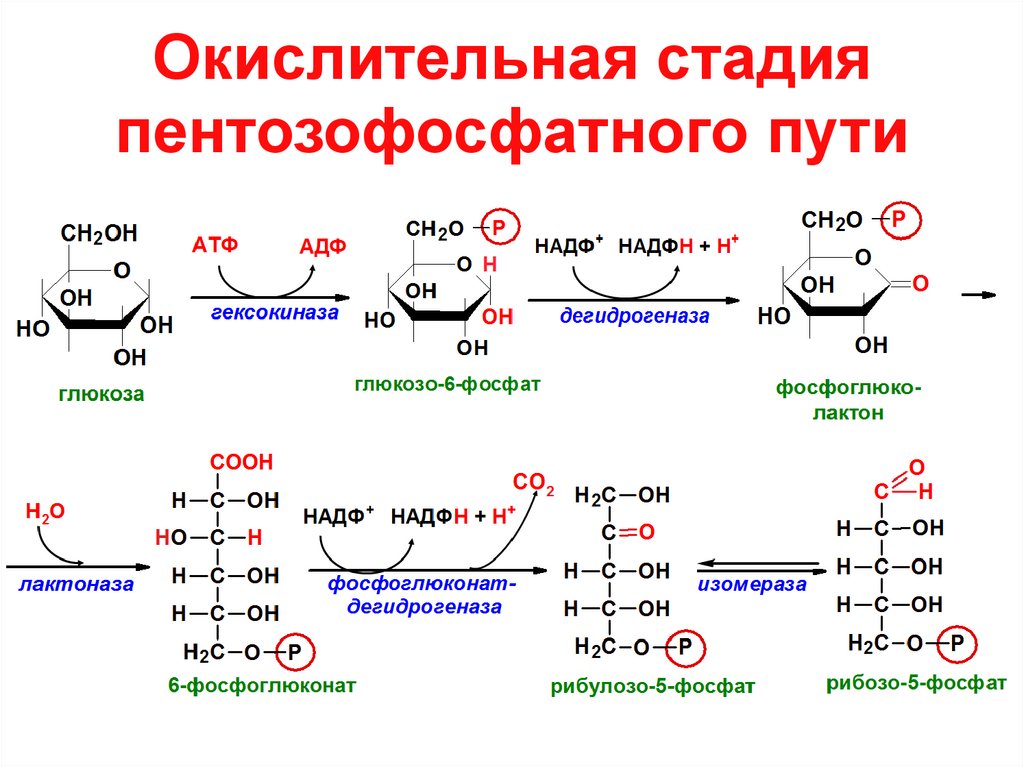 Если существуют другие проблемы, то это становится новым диагнозом, и затем необходимо обсудить, какие действия необходимо предпринять.
Если существуют другие проблемы, то это становится новым диагнозом, и затем необходимо обсудить, какие действия необходимо предпринять.
Владелец/лицо, принимающее решения: Группа аварийного восстановления ИТ (председатель: Менеджер по ликвидации чрезвычайных ситуаций)
15 Диагноз изменился? :
Если диагноз изменился, нужно ли привлекать другую третью сторону или изменить задание существующей?
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ-отдела
16 Тест :
Если считается, что неисправность устранена, то требуется формальное тестирование и подтверждение, основанное на требовании к исправлению, определенному в пункте 12. , За этим наблюдает менеджер по инцидентам.
NB: как минимум это должно включать модульное, системное, интеграционное и регрессионное тестирование.
Владелец/лицо, принимающее решения: При необходимости
17 Проверка прошла успешно? :
Проверка подтверждена как успешная?
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ
18 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе выполнения и обновить группу аварийного восстановления ИТ. Запишите все действия с момента последнего обновления в журнале инцидентов.
Запишите все действия с момента последнего обновления в журнале инцидентов.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
19 Восстановление систем :
Восстановление систем в порядке, заранее определенном в руководствах по процессам для подразделений обзор, проводимый сразу же после устранения бедствия со всеми ключевыми людьми, чтобы гарантировать, что никакие детали не будут потеряны из-за задержек или более позднего акцента на ключевых проблемах.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
21 Вызвать список действий :
Обеспечить своевременное выполнение действий, поднятых в горячем отчете
Владелец/лицо, принимающее решения: Руководитель ИТ DRP) официально считается закрытым.
Владелец/лицо, принимающее решение: Руководитель отдела ИТ
21 Работа в обычном режиме : Управление системами возвращается к устойчивому состоянию
Так же, как и для ПРОЦЕСС ВОССТАНОВЛЕНИЯ СИСТЕМЫ Ниже я перечисляю ряд действий, которые вы можете рассмотреть, и они должны быть помещены в простую блок-схему процесса (PFD). Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддались искушению использовать такие инструменты, как Visio, и остановить легкое обновление PFD в дальнейшем.
Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддались искушению использовать такие инструменты, как Visio, и остановить легкое обновление PFD в дальнейшем.
Восстановление после сбоя инфраструктуры
В случае серьезного сбоя инфраструктуры персонал организации должен будет провести расследование и при необходимости привлечь третьи стороны. Решение будет представлять собой объединение усилий обеих сторон, работающих как единая команда.
Процесс восстановления системы описан более подробно в следующих разделах с использованием блок-схемы процесса (PFD) и подробных описаний каждой задачи после PFD.
Аппаратное обеспечение (за исключением устройств конечного пользователя), поддерживаемое ИТ-отделом, указано в Приложении B.
Какие контракты на техническое обслуживание/восстановление существуют для оборудования? Являются ли ПК, ноутбуки и принтеры товаром? Они застрахованы? А МФУ?
Аппаратное обеспечение инфраструктуры, указанное в Приложении B, поддерживается ИТ-отделом, который будет …………….
В долгосрочной перспективе предполагается, что DRaaS будет использоваться для обеспечения «мгновенного» резервного копирования.
Процесс восстановления
Процесс восстановления подробно описан ниже. В Приложении D представлена логическая и физическая архитектура приложения для работы с данными, которая показывает, какие приложения работают на каких серверах и где хранятся данные. Это используется для определения последствий отключения (или потери) сервера.
Так же, как и для ПРОЦЕСС ВОССТАНОВЛЕНИЯ СИСТЕМЫ Ниже я перечисляю ряд действий, которые вы можете рассмотреть, и они должны быть помещены в простую блок-схему процесса (PFD). Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддались искушению использовать такие инструменты, как Visio, и остановить легкое обновление PFD в дальнейшем.
ПРОЦЕСС ВОССТАНОВЛЕНИЯ ИНФРАСТРУКТУРЫ
0 Произошел значительный аппаратный сбой :
Серьезный аппаратный сбой, в результате которого одна или несколько ключевых систем (приоритеты 1 и 2 в списке приложений в этом документе) становятся недоступными.
Владелец/Решение <Создатель: MD/CEO
1 Бедствие ?
MD/CEO информирует руководителя отдела информационных технологий о мероприятии. Управляющий директор/генеральный директор, руководитель ИТ-отдела и операционный директор решают, следует ли классифицировать это как стихийное бедствие.
Владелец/лицо, принимающее решение: управляющий директор/генеральный директор/руководитель отдела ИТ/операционный директор
2 DRP активирован :
План аварийного восстановления (DRP) официально отмечен как запущенный.
Владелец/лицо, принимающее решение: Начальник отдела ИТ
3 Краткий отчет менеджера по чрезвычайным ситуациям
Начальник ИТ звонит менеджеру по чрезвычайным ситуациям, чтобы проинформировать его о ситуации и подтвердить необходимость активации DRP.
Владелец/лицо, принимающее решение: руководитель отдела ИТ
4 Обеспечение активации ППГ :
Убедитесь, что все соответствующие планы обеспечения непрерывности бизнеса были задействованы через процессы BCP. Они содержат ряд действий, дополняющих DRP и поэтому не дублирующихся в нем.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
5 Доступ к папке DRP :
Всем ИТ-руководителям доступ к плану аварийного восстановления и мобилизация их команд по мере необходимости
Владелец/лицо, принимающее решения: Группа аварийного восстановления ИТ
6 Информировать IT SMT о том, что DRP запущен :
Отправить электронное письмо и мгновенное сообщение/текстовое сообщение в группу аварийного восстановления ИТ (как указано в разделе « Роли и обязанности ») в этом документе.)
Позвоните руководителю ИТ, чтобы обсудить ситуации и дальнейшие действия.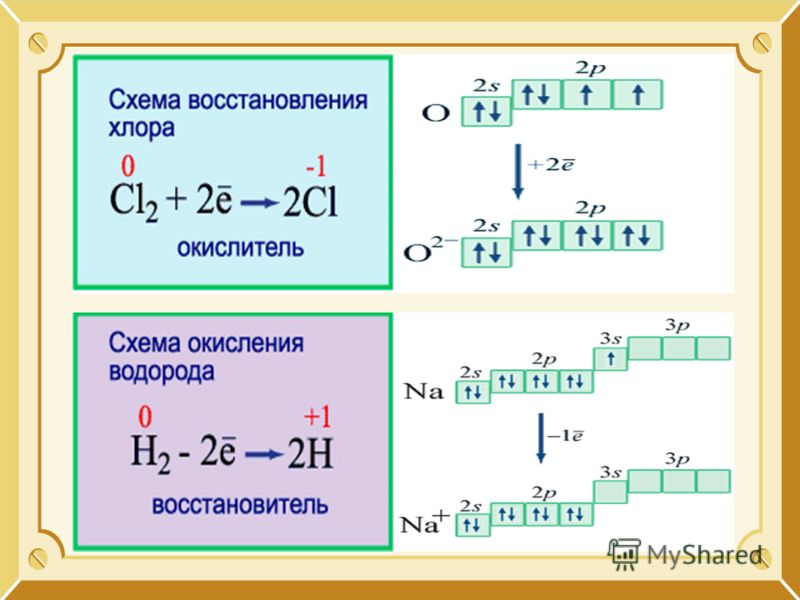
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
7 Проведение первоначального инструктажа группы аварийного восстановления:
Менеджер по инцидентам организует и проводит первичный инструктаж для группы аварийного восстановления ИТ, ознакомившись с проблемой совместно с руководителем отдела ИТ и персоналом земля.
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
8 Первоначальный диагноз :
Официально изложите возникшую проблему и сделайте первоначальный диагноз относительно предполагаемой основной причины (причин) проблемы. Консультировать команду IT DR. Примите к сведению их взгляды и идеи.
Владелец/лицо, принимающее решения: Менеджер по чрезвычайным ситуациям
9 3-я проблема? :
Группа аварийного восстановления ИТ для обсуждения ситуации и принятия решения о привлечении третьей стороны, а также краткого описания, которое должно быть предоставлено им.
Будет рассмотрено использование гарантий и покрытия глобальной инфраструктуры (если таковое имеется), а также привлечение специализированной компании по аварийному восстановлению.
Список компаний, осуществляющих аварийное восстановление, приведен в Приложении E.
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ (председатель: руководитель ИТ-отдела)
10 Привлечение третьей стороны для выполнения работы выполнять работу, при необходимости оформляя заказ на экстренный заказ
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ-отдела
11 Обновить команду IT DR :
Сопоставить данные о ходе работы и обновить группу IT DR. Если позволяет время, создайте короткую информационную записку.
Записывать все действия в журнал инцидентов.
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
12 Диагностика, планирование и исправление :
Команда аварийно-спасательных служб ИТ решает, кто поддерживает связь с третьей стороной (если задействована), кто что делает в команде и когда
Примечание: Этот шаг также требует определения того, что будет означать «фиксированный». Это должно быть объективно.
Это должно быть объективно.
NB: Этот шаг повторяется.
Владелец/лицо, принимающее решения: Группа аварийного восстановления ИТ (Председатель: Менеджер по устранению инцидентов)
13 Устранена неисправность:
Считает ли группа аварийного восстановления ИТ, что неисправность устранена и системы можно восстановить?
Владелец/лицо, принимающее решение: группа аварийного восстановления ИТ (председатель: руководитель ИТ-отдела)
14 Просмотрите диагноз:
Просмотрите диагноз, чтобы убедиться, что это все еще считается проблемой. Если существуют другие проблемы, то это становится новым диагнозом, и затем необходимо обсудить, какие действия необходимо предпринять.
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ (председатель: Менеджер по ликвидации чрезвычайных ситуаций)
15 Диагноз изменился? :
Если диагноз изменился, нужно ли привлекать другую третью сторону или изменить задание существующей?
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ (председатель: руководитель ИТ-отдела)
16 Тест :
Если считается, что неисправность устранена, то требуется официальное тестирование и подписание в соответствии с требованием для исправления, указанного в пункте 12. За этим следит менеджер по инцидентам.
За этим следит менеджер по инцидентам.
NB: как минимум это должно включать модульное, системное, интеграционное и регрессионное тестирование.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций+ при необходимости
17 Проверка прошла успешно? :
Проверка подтверждена как успешная?
Владелец/лицо, принимающее решение: группа аварийного восстановления ИТ (председатель: руководитель ИТ-отдела)
18 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе выполнения и обновить группу аварийного восстановления ИТ. Запишите все действия с момента последнего обновления в журнале инцидентов.
Владелец/Прат для принятия решений: управляющий инцидентами
19 Инфраструктура восстановления :
Восстановление инфраструктуры в устойчивое состояние
Владелец/Пресс -решающий изученный» обзор, проводимый сразу после устранения бедствия со всеми ключевыми людьми, чтобы гарантировать, что никакие детали не будут потеряны из-за задержек или более позднего акцента на ключевых проблемах.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
21 Вызвать список действий :
Обеспечить своевременное выполнение действий, упомянутых в горячем разборе
Владелец/лицо, принимающее решения: руководитель ИТ-отдела заранее установленный порядок в руководствах по процессам отдела
Владелец/лицо, принимающее решения: Группа аварийного восстановления ИТ
23 DRP закрыто:
План аварийного восстановления (DRP) официально отмечен как закрытый.
Владелец/лицо, принимающее решения: руководитель IT
24 Business Run «Как обычно»
Управление систем возвращается в стационарное состояние
Аварийный переезд
так же, как и для . ПРОЦЕСС ВОССТАНОВЛЕНИЯ СИСТЕМЫ Ниже я перечисляю ряд действий, которые вы можете рассмотреть, и они должны быть помещены в простую блок-схему процесса (PFD). Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддались искушению использовать такие инструменты, как Visio, и остановить легкое обновление PFD в дальнейшем.
Я предлагаю использовать «фигуры» блок-схемы в PowerPoint, поскольку у большинства людей есть доступ к этому инструменту, и будущие поколения смогут вносить поправки в PFD. Так много людей поддались искушению использовать такие инструменты, как Visio, и остановить легкое обновление PFD в дальнейшем.
ПРОЦЕСС ВОССТАНОВЛЕНИЯ ПРИ АВАРИЙНОМ ПЕРЕМЕЩЕНИИ
0 Произошла значительная потеря среды :
) быть недоступным.
Это может быть вызвано, например, пожаром в центре обработки данных
Владелец/лицо, принимающее решение: MD/CEO
1 Бедствие ?
MD/CEO информирует руководителя отдела информационных технологий о мероприятии. Управляющий директор/генеральный директор, руководитель ИТ-отдела и операционный директор решают, следует ли классифицировать это как стихийное бедствие.
Владелец/лицо, принимающее решение: управляющий директор/генеральный директор/руководитель отдела ИТ/операционный директор
2 Согласен с альтернативным местоположением
Оценить альтернативное местоположение. SWB Estates может предложить подходящую альтернативу утраченному участку. Если нет, то может понадобиться переноска или что-то подобное либо в компании Estates, либо в специализированной компании по восстановлению после стихийных бедствий 9.0007
SWB Estates может предложить подходящую альтернативу утраченному участку. Если нет, то может понадобиться переноска или что-то подобное либо в компании Estates, либо в специализированной компании по восстановлению после стихийных бедствий 9.0007
Владелец/лицо, принимающее решение: Начальник отдела инфраструктуры
3 Подготовка альтернативного места и проверка
Альтернативное место требует соответствующих кабелей, электропитания и опор, а также запасного комплекта, если исходное отсутствует.
После того, как он будет установлен, его необходимо протестировать, чтобы убедиться, что он соответствует назначению.
Владелец/лицо, принимающее решения: Начальник отдела инфраструктуры
4 Проверка прошла успешно?
Проверка работоспособности прошла успешно? Все ли работает так, как ожидалось (или настолько близко, насколько это необходимо).
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ-отдела
5 Переход в альтернативное местоположение
Восстановление данных и приложений на новом оборудовании в новой среде.
Владелец/лицо, принимающее решения: Руководитель инфраструктуры
6 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе работы и обновить группу аварийного восстановления ИТ. Если позволяет время, создайте короткую информационную записку.
Запись всех действий в журнал инцидентов.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
7 Убедитесь, что BCP инициированы :
Убедитесь, что все соответствующие планы обеспечения непрерывности бизнеса были инициированы через процессы BCP. Они содержат ряд действий, дополняющих DRP и поэтому не дублирующихся в нем.
Владелец/лицо, принимающее решения: менеджер по ликвидации чрезвычайных ситуаций
8 Краткий отчет менеджера по чрезвычайным ситуациям
Начальник отдела ИТ звонит менеджеру по чрезвычайным ситуациям, чтобы проинформировать его о ситуации и подтвердить необходимость активации DRP.
Владелец/лицо, принимающее решение: Руководитель ИТ-отдела
9 Доступ к папке DRP :
Всем ИТ-руководителям доступ к плану аварийного восстановления и мобилизация их команд по мере необходимости 10 DRP запущен :
План аварийного восстановления (DRP) официально отмечен как запущенный.
Владелец/лицо, принимающее решение: руководитель ИТ-подразделения
11 Информировать ИТ-SMT о вызове DRP :
Отправить электронное письмо и мгновенное сообщение/текстовое сообщение в группу аварийного восстановления ИТ (как указано в разделе « Роли и обязанности ») в этом документе.)
Позвоните руководителю отдела ИТ, чтобы обсудить ситуации и дальнейшие действия.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
12 Провести первоначальный брифинг группы аварийного восстановления:
Менеджер по инцидентам организует и проводит первоначальный инструктаж для группы аварийного восстановления ИТ, ознакомившись с проблемой совместно с руководителем ИТ и персоналом земля.
Владелец/лицо, принимающее решения: Менеджер по чрезвычайным ситуациям
13 Возврат?
Готова ли среда устойчивого состояния к повторному использованию?
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ-отдела
14 Просмотр вариантов возврата Использование облачных сервисов и сторонних хостингов.
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ
15 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе выполнения и обновить группу аварийного восстановления ИТ. Если позволяет время, создайте короткую информационную записку.
Запишите все действия в журнал инцидентов.
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
16 Проведение 1-го оперативного разбора :
Проведение обзора «извлеченных уроков», проводимого сразу после завершения переезда во временное место со всеми ключевыми людьми, чтобы убедиться, что никакие детали потеряны из-за задержек или более позднего акцента на ключевых вопросах.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
17 Вызов 1-го списка действий :
Обеспечить своевременное выполнение действий, указанных в 1-м горячем отчете
Владелец/лицо, принимающее решение: Руководитель ИТ-отдела
18 Тестовая среда
Тестирование среды устойчивого состояния
Владелец/лицо, принимающее решение: IT DR Команда
19 Проверка прошла успешно?
Проверка работоспособности прошла успешно? Все ли работает так, как ожидалось (или настолько близко, насколько это необходимо).
Владелец/лицо, принимающее решение: Группа аварийного восстановления ИТ
20 Обновление группы аварийного восстановления ИТ :
Сопоставьте данные о ходе выполнения на сегодняшний день и обновите группу IT DR. Если позволяет время, создайте короткую информационную записку.
Запись всех действий в журнал инцидентов.
Владелец/лицо, принимающее решение: Менеджер по устранению инцидентов
21 Решение проблем
Все, что было признано неприемлемым во время тестирования, должно быть исправлено.
Владелец/лицо, принимающее решение: Руководитель инфраструктуры
22 Обновить группу аварийного восстановления ИТ :
Сопоставить данные о ходе работы и обновить группу аварийного восстановления ИТ. Если позволяет время, создайте короткую информационную записку.
Запишите все действия в журнал инцидентов.
Владелец/лицо, принимающее решения: Менеджер по устранению инцидентов
23 Переход к обычной среде
Восстановление данных и приложений на новом оборудовании в новой среде.
Владелец/лицо, принимающее решения: Руководитель инфраструктуры
24 Проведение второго оперативного разбора :
Проведение обзора «извлеченных уроков», проводимого сразу после завершения возврата к среде стабильного состояния со всеми ключевыми людьми для обеспечения ни одна деталь не утеряна из-за задержек или более позднего акцента на ключевых вопросах.
Владелец/лицо, принимающее решения: Менеджер по ликвидации чрезвычайных ситуаций
25 Вызвать 2-й список действий :
Обеспечить своевременное выполнение действий, упомянутых в 1-м горячем разборе DRP Closed:
План аварийного восстановления (DRP) официально отмечен как закрытый.
Владелец/лицо, принимающее решение: руководитель отдела ИТ
27 Работа в обычном режиме
Управление системами возвращается к устойчивому процессу
Приложение A
Для каждой системы, используемой в организации, укажите Продукт, Поставщика, их контактную информацию и сведения о том, кто использует систему в бизнесе .
Приложение B
Перечислите всю аппаратную инфраструктуру на объекте: название продукта, сайт, местонахождение, тип, производитель, модель, серийный номер/метка обслуживания, номер детали, тип гарантии и дата окончания. Это важное мероприятие, и вы можете включить только его часть, но полный список — это хороший способ полностью понять ваше имущество и, в первую очередь, избежать катастрофы!
Приложение C
Список приложений, поддерживаемых ИТ: Заполняется [Роль] доступна или нет, есть ли сторонняя обложка или нет (и что это такое) и где хранится резервная копия.
Приложение D
Подробная информация о логической и физической архитектуре данных приложения в этом разделе показывает, какие системы работают на каких серверах и как они взаимодействуют друг с другом. Лучше всего использовать схематическое представление, я использую прямоугольник для каждого сервера, «короткие, толстые» цилиндры для баз данных и овалы для приложений, помещая данные и представление приложений в серверные блоки. Затем я соединяю потоки данных между ними с помощью линий. Если вы используете PowerPoint, у вас будет что-то, что может быть легко обновлено в будущем тем, кто унаследует план
Это позволяет быстро оценить конечные последствия отключения сервера и принять соответствующие меры .
Приложение E
Сначала перечислите компании, предоставляющие услуги аварийного восстановления, но вскоре после этого заключите с ними соглашение о восстановлении ваших сайтов, если/когда это потребуется
Блок-схема восстановления базы данных SQL Server
Существует множество проблем это может привести к сценариям потери данных. Первое, что должен сделать каждый хороший администратор базы данных, — это обеспечить бережное отношение к периоду после стихийного бедствия. Чтобы обеспечить возможность восстановления данных или отмены вредоносных изменений, настоятельно рекомендуется предпринять следующие шаги сразу после инцидента:
- Отсоединить базу данных
- Создание копий файлов MDF и LDF базы данных
- Переместите копии MDF и LDF на другой сервер и прикрепите их
- Скопируйте все существующие резервные копии базы данных или журнала транзакций на другой сервер
После принятия мер предосторожности после инцидента необходимо выбрать наиболее подходящий сценарий восстановления, чтобы обеспечить максимальную скорость успешного восстановления.
Эта статья предназначена для того, чтобы помочь пользователям выбрать лучшее решение для восстановления для их конкретного сценария аварийного восстановления при использовании ApexSQL Recover, инструмента восстановления SQL Server, способного восстанавливать удаленные, удаленные или усеченные данные и объекты, откатывать нежелательные изменения или даже извлекать таблицы. структуру и данные непосредственно из резервных копий базы данных. Кроме того, ApexSQL Recover может восстанавливать удаленные большие двоичные объекты или даже извлекать их из действующих баз данных в виде файлов больших двоичных объектов.
Ниже представлена блок-схема, призванная помочь любому пользователю выбрать наиболее подходящий подход для своего сценария восстановления:
Дополнительные сведения о конкретных сценариях восстановления, которые могут привести к частичному восстановлению:
- Соединение с a База данных в реальном времени недоступна, но существует полная резервная копия базы данных
В этом случае для получения максимальных результатов следует использовать функцию Извлечь из резервной копии базы данных.
Эта опция позволяет пользователю извлекать данные и/или структуру только для определенных таблиц вместо того, чтобы восстанавливать полную резервную копию базы данных в другом месте и извлекать оттуда, экономя время и место. Восстановленные данные могут быть добавлены в новую базу данных или в виде SQL-скрипта для упрощения процесса восстановления. Полное пошаговое руководство доступно в этой статье. - R ecover ing из операций DELETE или DROP, когда база данных не находится в модели полного восстановления
Полная функциональность ApexSQL Recover доступна только в том случае, если база данных находится в модели полного восстановления. Поскольку простая модель восстановления не гарантирует, что информация, необходимая для восстановления ApexSQL, будет доступна из-за отсутствия записей в журнале транзакций, поскольку SQL Server перезаписывает информацию в ldf, чтобы свести потребление дискового пространства к минимуму.
Это оставляет только данные в файле MDF в качестве источника информации, и эти данные также регулярно перезаписываются SQL Server и, следовательно, ненадежны и могут быть уже утеряны.
Имея все это в виду, диапазон восстановления ограничен при работе с базами данных с простой моделью восстановления. Следует иметь в виду, что важно переключить базу данных в автономный режим сразу после подтверждения необходимости восстановления, чтобы попытаться и сохраняйте исходную информацию восстановления как в ldf, так и в mdf как можно более полной. - Восстановление после операций DROP или DELETE, когда журнал транзакций усечен, а резервные копии недоступны
В случае, когда выполняется восстановление из операций DELETE или DROP с таблицами, ApexSQL Recover использует данные из файлов журнала транзакций (в сети, из резервной копии или отсоединенных) для выполнения восстановления. Если файлы журнала транзакций недоступны, восстановление все равно можно выполнить, так как ApexSQL Recover проверит, существуют ли еще эти данные в файле MDF базы данных, поскольку SQL Server удаляет данные логически, немедленно помечая данные как удаленные, когда на самом деле данные будут перезаписаны в файле MDF при первом подходящем случае, что может произойти через несколько часов или даже дней в некоторых случаях.
Этот факт делает действия после инцидента, описанные в начале, чрезвычайно важными и обязательными для обеспечения достойных шансов на восстановление. - Восстановление из операций объекта UPDATE, INSERT, ALTER, CREATE или DROP, когда база данных находится в простая модель восстановления
Чтобы средство восстановления ApexSQL (а также журнал ApexSQL) отображало/восстанавливало все транзакции для конкретной базы данных, модель восстановления базы данных должна быть установлена на «полное». Если выбрана простая модель восстановления, файлы журнала транзакций будут содержать лишь ограниченный объем данных, и для аудита/восстановления будет доступна только небольшая часть самых последних операций.
- Аудит или восстановление неполная цепочка файлы журнала транзакций
Когда файл журнала транзакций в сети был усечен, чтобы иметь возможность ожидать полного диапазона результатов, необходимо предоставить полную цепочку резервных копий журнала транзакций, чтобы ApexSQL Recover (а также журнал ApexSQL) мог создать историческое восстановление и проследить историю строк.
Это особенно важно при восстановлении операций UPDATE, поскольку каждое UPDATE имеет по крайней мере инструкцию INSERT в качестве предшествующей, а история данных может различаться. Если полная цепочка резервных копий журнала транзакций недоступна, результаты аудита/восстановления могут быть неполными, а в операциях UPDATE отсутствуют полные сведения. Кроме того, процесс восстановления будет иметь сниженную производительность, поскольку инструментам придется выполнять дополнительную обработку, чтобы создать полную историю, когда цепочка журнала транзакций разорвана.
29 июля 2015 г.
Процесс планирования аварийного восстановления | Процесс аварийного восстановления
Джеффри Х. Уолд
Это первая из трех частей, описывающих процесс планирования аварийного восстановления. Исходя из различных соображений, рассмотренных на этапе планирования, сам процесс и связанная с ним методология могут быть столь же полезными, как и окончательный письменный план.
Большинство предприятий в значительной степени зависят от технологий и автоматизированных систем, и их сбой даже на несколько дней может привести к серьезным финансовым потерям и поставить под угрозу выживание.
Непрерывная деятельность организации зависит от осведомленности руководства о возможных стихийных бедствиях, его способности разработать план по минимизации нарушений критических функций и способности целесообразно и успешно восстанавливать операции.
План аварийного восстановления — это всеобъемлющее описание последовательных действий, которые необходимо предпринять до, во время и после аварии. План должен быть задокументирован и протестирован, чтобы обеспечить непрерывность операций и доступность критически важных ресурсов в случае бедствия.
Основная цель планирования аварийного восстановления — защитить организацию в случае, если все или часть ее операций и/или компьютерных служб станут непригодными для использования. Готовность является ключевым моментом. Процесс планирования аварийного восстановления должен свести к минимуму прерывание операций и обеспечить определенный уровень организационной стабильности и упорядоченное восстановление после аварии.
Другие цели планирования аварийного восстановления включают:
- Обеспечение чувства безопасности
- Минимизация риска задержек
- Обеспечение надежности резервных систем
- Предоставление стандарта для тестирования плана.
- Минимизация принятия решений во время стихийного бедствия
Диаграмма, состоящая из трех частей, иллюстрирует процесс планирования аварийного восстановления . Методология описана ниже.
1. Получить обязательство высшего руководства
Высшее руководство должно поддерживать и участвовать в разработке процесса планирования аварийного восстановления. Руководство должно нести ответственность за координацию плана аварийного восстановления и обеспечение его эффективности внутри организации.
Для разработки эффективного плана необходимо выделить достаточно времени и ресурсов. Ресурсы могут включать как финансовые соображения, так и усилия всего задействованного персонала.
2. Создание комитета по планированию
Комитет по планированию должен быть назначен для надзора за разработкой и реализацией плана. В комитет по планированию должны входить представители всех функциональных областей организации. В число ключевых членов комитета должны входить менеджер по операциям и менеджер по обработке данных. Комитет также должен определить объем плана.
3. Провести оценку рисков
Комитет по планированию должен подготовить анализ рисков и анализ воздействия на бизнес, который включает ряд возможных бедствий, включая природные, технические и человеческие угрозы.
Следует проанализировать каждую функциональную область организации, чтобы определить потенциальные последствия и воздействие, связанные с несколькими сценариями стихийных бедствий. В процессе оценки рисков следует также оценить безопасность важнейших документов и записей актов гражданского состояния.
Традиционно пожар представлял наибольшую угрозу для организации. Однако следует также учитывать преднамеренное уничтожение человеком. В плане должен быть предусмотрен «худший случай»: разрушение основного здания.
Важно оценить влияние и последствия потери информации и услуг. Комитет по планированию также должен проанализировать затраты, связанные с минимизацией потенциального воздействия.
4. Установите приоритеты для обработки и операций
Критические потребности каждого отдела в организации должны быть тщательно оценены в таких областях, как:
• Функциональные операции
• Ключевой персонал
• Информация
• Системы обработки
• Служба
• Документация
• Основные записи
• Политики и процедуры
Необходимо проанализировать обработку и операции, чтобы определить максимальное количество времени, в течение которого отдел и организация могут работать без каждой критической системы.
Критические потребности определяются как необходимые процедуры и оборудование, необходимые для продолжения работы, если отдел, компьютерный центр, главный объект или их комбинация будут уничтожены или станут недоступны.
Метод определения критических потребностей отдела заключается в документировании всех функций, выполняемых каждым отделом. После определения основных функций операции и процессы следует ранжировать в порядке приоритета: существенные, важные и второстепенные.
5. Определение стратегии восстановления
Необходимо изучить и оценить наиболее практичные альтернативы обработки в случае бедствия. Важно учитывать все аспекты организации, такие как:
• Помещения
• Аппаратное обеспечение
• Программное обеспечение
• Коммуникации
• Файлы данных
• Обслуживание клиентов
• Операции пользователей
• MIS
• Системы конечных пользователей
• Другое операции обработки
Альтернативы, зависящие от оценки функции компьютера, могут включать:
• Горячие объекты
• Теплые объекты
• Холодные объекты
• Взаимные соглашения
• Два центра обработки данных
• Несколько компьютеров
• Сервисные центры
• Консорциум
• Оборудование, поставляемое поставщиком
• Комбинации вышеуказанного
Письменные соглашения на должны быть подготовлены конкретные выбранные альтернативы восстановления, включая следующие особые соображения:
• Срок действия контракта
• Условия расторжения
• Тестирование
• Затраты
• Особые процедуры безопасности
• Уведомление об изменениях в системе
• Часы работы
• Специальное аппаратное и другое оборудование, необходимое для обработки
• Требования к персоналу
• Обстоятельства, составляющие чрезвычайную ситуацию
• Процесс переговоров о продлении обслуживания
• Гарантия совместимости
• Доступность
• Требования к ресурсам, не относящимся к мэйнфреймам
• Приоритеты
• Другие договорные вопросы
6. Сбор данных
Рекомендуемые материалы для сбора данных и документация включают в себя:
• Список резервных позиций
• Важные номера телефонов
• Инвентаризация средств связи
• Реестр распределения
• Инвентаризация документации
• Инвентаризация оборудования
• Инвентаризация форм
• Инвентаризация страховых полисов
• Основное компьютерное оборудование Инвентаризация
• Основной список вызовов
• Основной список поставщиков
• Инвентаризация аппаратного и программного обеспечения микрокомпьютеров
• Контрольный список уведомлений
• Инвентаризация канцелярских принадлежностей
• Инвентаризация складских помещений
• Графики резервного копирования/хранения программного обеспечения и файлов данных
• Инвентаризация телефонов
• Спецификации временного местоположения
• Другие материалы и документация
Чрезвычайно полезно разработать предварительно отформатированные формы для облегчения процесса сбора данных.
7. Организуйте и задокументируйте письменный план
Необходимо подготовить план содержания плана, чтобы направлять разработку подробных процедур. Высшее руководство должно рассмотреть и утвердить предложенный план. План может быть в конечном итоге использован для оглавления после окончательной редакции. Другими преимуществами этого подхода являются то, что он:
• Помогает организовать подробные процедуры
• Идентифицирует все основные шаги перед началом записи
• Идентифицирует избыточные процедуры, которые нужно написать только один раз.
• Предоставляет дорожную карту для разработки процедур
Должен быть разработан стандартный формат для облегчения написания подробных процедур и документации другой информации, которая должна быть включена в план. Это поможет гарантировать, что план действий на случай стихийных бедствий следует единообразному формату и позволит постоянно поддерживать план. Стандартизация особенно важна, если в написании процедур участвует более одного человека.
План должен быть тщательно разработан, включая все подробные процедуры, которые будут использоваться до, во время и после стихийного бедствия. Разработка подробных процедур может оказаться нецелесообразной до тех пор, пока не будут определены резервные альтернативы.
Процедуры должны включать методы ведения и обновления плана для отражения любых значительных внутренних, внешних или системных изменений. Процедуры должны предусматривать регулярный пересмотр плана ключевым персоналом организации.
План аварийного восстановления должен быть структурирован с использованием группового подхода. Конкретные обязанности должны быть возложены на соответствующую команду для каждой функциональной области компании.
В организации должны быть группы, отвечающие за административные функции, объекты, логистику, поддержку пользователей, резервное копирование компьютеров, восстановление и другие важные области.
Структура организации на случай непредвиденных обстоятельств может не совпадать с существующей организационной схемой. Организация на случай непредвиденных обстоятельств обычно состоит из групп, отвечающих за основные функциональные области, такие как:
• Административные функции
• Объекты
• Логистика
• Поддержка пользователей
• Резервное копирование компьютеров
• Восстановление
• Другие важные области
Группа управления особенно важна, поскольку она координирует процесс восстановления. Команда должна оценить катастрофу, активировать план восстановления и связаться с руководителями группы.
Группа управления также контролирует, документирует и контролирует процесс восстановления. Члены управленческой команды должны принимать окончательные решения при определении приоритетов, политик и процедур.
У каждой команды есть определенные обязанности, которые необходимо выполнить, чтобы обеспечить успешное выполнение плана. Команды должны иметь назначенного менеджера и заместителя на случай, если менеджер команды недоступен. Другие члены команды также должны иметь конкретные задания, где это возможно.
8. Разработка критериев и процедур тестирования
Важно, чтобы план тщательно тестировался и оценивался на регулярной основе (не реже одного раза в год). Процедуры тестирования плана должны быть задокументированы. Тесты дадут организации уверенность в том, что все необходимые шаги включены в план. Другие причины для тестирования включают:
• Определение осуществимости и совместимости резервных средств и процедур
• Определение областей в плане, которые нуждаются в модификации
• Обучение руководителей и членов группы
• Демонстрация способности организации к восстановлению
• Обеспечение мотивации для поддержки и обновления плана аварийного восстановления
9. Тестирование плана
После завершения процедур тестирования Первоначальная проверка плана должна быть выполнена путем проведения структурированного сквозного теста. Тест предоставит дополнительную информацию о любых дальнейших шагах, которые, возможно, потребуется включить, изменениях в процедурах, которые не являются эффективными, и других соответствующих корректировках. План следует обновить, чтобы исправить любые проблемы, выявленные во время тестирования. Первоначально тестирование плана следует проводить по частям и в нерабочее время, чтобы свести к минимуму сбои в общей работе организации.
Типы тестов включают:
• Контрольный список тестов
• Симуляционные тесты
• Параллельные тесты
• Тесты полного прерывания
10. Утверждение плана
После написания и тестирования плана аварийного восстановления план должен быть утвержден высшее руководство. Высшее руководство несет полную ответственность за то, чтобы у организации был задокументированный и проверенный план.
Руководство отвечает за:
• Установление политик, процедур и обязанностей для комплексного планирования на случай непредвиденных обстоятельств.
• Ежегодный пересмотр и утверждение плана действий в чрезвычайных ситуациях, документирование таких проверок в письменной форме
Если организация получает обработку информации от сервисного бюро, руководство также должно:
• Оценить адекватность планов действий в чрезвычайных ситуациях для своего сервисного бюро план на случай непредвиденных обстоятельств совместим с планом бюро обслуживания
Заключение
Планирование аварийного восстановления включает в себя нечто большее, чем внешнее хранение или обработку резервных копий. Организации также должны разработать письменные комплексные планы аварийного восстановления, которые охватывают все критически важные операции и функции бизнеса. План должен включать задокументированные и проверенные процедуры, соблюдение которых обеспечит постоянную доступность критически важных ресурсов и непрерывность операций.
Вероятность бедствия, происходящего в организации, очень неопределенна. Однако план на случай стихийного бедствия аналогичен страхованию ответственности: он обеспечивает определенный уровень комфорта, зная, что если произойдет крупная катастрофа, она не приведет к финансовой катастрофе. Одной только страховки недостаточно, поскольку она может не компенсировать неисчислимые потери бизнеса во время прерывания или бизнеса, который никогда не возобновится.
Другие причины для разработки комплексного плана аварийного восстановления включают:
• Минимизация потенциальных экономических потерь.
• Уменьшение потенциального воздействия
• Уменьшение вероятности возникновения
• Уменьшение сбоев в работе
• Обеспечение организационной стабильности
• Обеспечение упорядоченного восстановления
• Минимизация страховых взносов
• Уменьшение зависимости от определенных ключевых лиц
• Защита активов организации
• Обеспечение безопасности персонала и клиентов
• Минимизация принятия решений во время стихийного бедствия
• Минимизация юридической ответственности
Во второй части этой серии будут описаны конкретные методы организации и написания комплексного плана аварийного восстановления.
Это вторая из трех частей серии, в которой описываются конкретные методы организации и написания комплексного плана аварийного восстановления. В первой части этой серии описан процесс разработки подробного плана аварийного восстановления.
Хорошо организованный план аварийного восстановления напрямую влияет на возможности восстановления в организации. Содержание плана должно следовать логической последовательности и быть написано в стандартном и понятном формате.
Эффективная документация и процедуры чрезвычайно важны для плана аварийного восстановления. Для разработки плана необходимы значительные усилия и время. Однако большинство планов сложны в использовании и быстро устаревают. Плохо написанные процедуры могут сильно разочаровать. Хорошо написанные планы сокращают время, необходимое для прочтения и понимания процедур, и, следовательно, увеличивают шансы на успех, если план необходимо использовать. Хорошо написанные планы также кратки и точны.
Стандартный формат
Стандартный формат процедур должен быть разработан для обеспечения последовательности и соответствия всему плану. Стандартизация особенно важна, если процедуры пишут несколько человек. Для написания плана используются два основных формата: справочная информация и учебная информация.
Справочная информация должна быть написана с использованием ориентировочных предложений, а для написания инструкций следует использовать императивный стиль. Изъявительные предложения имеют прямую структуру подлежащее-глагол-сказуемое, в то время как повелительные предложения начинаются с глагола (предполагается местоимение «вы») и дают указания, которым нужно следовать.
Рекомендуемая справочная информация включает:
• Цель процедуры
• Объем процедуры (например, местоположение, оборудование, персонал и время, связанные с тем, что охватывает процедура)
• Справочные материалы (т. е. другие руководства, информацию или материалы, которые следует ознакомиться)
• Документация с описанием применимых форм, которые необходимо использовать при выполнении процедур
• Разрешения с перечислением конкретных требуемых разрешений
• Особые политики, применимые к процедурам
Инструкции должны быть разработаны на предварительно напечатанном бланке. Предлагаемый формат инструктивной информации состоит в том, чтобы отделить заголовки, общие для каждой страницы, от подробностей процедур. Заголовки должны включать:
• Номер предметной категории и описание
• Номер и описание предметной подкатегории
• Номер страницы
• Номер редакции
• Дата замены
Методы написания
Процедуры должны быть четко изложены. Полезные методы написания подробных процедур включают в себя:
• Будьте конкретны. Напишите план, предполагая, что он будет реализован персоналом, совершенно незнакомым с функциями и операциями.
• Используйте короткие прямые предложения и делайте их простыми. Длинные предложения могут ошеломить или запутать читателя.
• Используйте тематические предложения в начале каждого абзаца.
• Используйте короткие абзацы. Длинные абзацы могут навредить читателю.
• Предлагайте по одной идее за раз. Две мысли обычно требуют двух предложений.
• Используйте глаголы активного залога в настоящем времени. Предложения с пассивным залогом могут быть длинными и могут быть неверно истолкованы.
• Избегайте жаргона.
• Используйте названия должностей (а не личные имена отдельных лиц), чтобы сократить требования к обслуживанию и пересмотру.
• Избегайте родовых существительных и местоимений, которые могут вызвать ненужные требования к пересмотру.
• Разработайте единообразие процедур, чтобы упростить процесс обучения и свести к минимуму исключения из условий и действий.
• Определите события, которые происходят параллельно, и события, которые должны происходить последовательно.
• Используйте описательные глаголы. Неописательные глаголы, такие как «сделать» и «взять», могут сделать процедуры чрезмерно многословными. Примеры описательных глаголов:
Получить Журнал подсчета
Активировать Создать Переместить
Сообщить Объявить Оплатить
Ответить Доставить Печать
Помочь Ввести Запись
Резервное копирование Объяснить Заменить
Файл Баланса Отчет
Сравнить Информировать Обзор планы касаются только деятельности, связанной с обработкой данных, комплексный план также будет включать области деятельности, не связанные с обработкой данных.
План должен иметь широкий охват, если он предназначен для эффективного устранения многих аварийных сценариев, которые могут повлиять на организацию.
«Наихудший сценарий» должен быть основой для разработки плана. Наихудшим сценарием является разрушение основного или первичного объекта
. Поскольку план написан на основе этой предпосылки, в менее критических ситуациях можно справиться, используя только необходимые части плана с незначительными (если таковые имеются) изменениями.
Предположения планирования
Каждый план аварийного восстановления имеет основу из предположений, на которых строится план. Предположения ограничивают обстоятельства, на которые направлен план.
Пределы определяют масштаб бедствия, к которому готовится организация. Предположения часто можно определить, задав следующие вопросы:
• Какое оборудование/объекты были уничтожены?
• Каковы сроки сбоя?
• Какие записи, файлы и материалы были защищены от уничтожения?
• Какие ресурсы доступны после стихийного бедствия:
– Персонал?
– Оборудование?
– Связь?
— Транспорт?
— Горячий сайт/альтернативный сайт?
Ниже приводится список типичных допущений планирования, которые следует учитывать при написании плана аварийного восстановления:
• Основной объект организации разрушен
• Персонал доступен для выполнения критических функций, определенных в плане
• Персонал может быть уведомлены и могут отчитываться перед резервной(ыми) площадкой(ами) для выполнения критически важных операций по обработке, восстановлению и реконструкции
• Уцелевшие складские помещения и материалы за пределами площадки
• План аварийного восстановления актуален
• Подмножества общего плана могут использоваться для восстановления после незначительных сбоев
• Доступен альтернативный объект
• Достаточный запас критических форм и расходных материалов хранится вне офиса, либо в альтернативном объект или внеплощадочное хранилище
• Имеется резервная площадка для оформления работ организации
• В распоряжении организации имеются необходимые междугородние и местные линии связи
• Возможен наземный транспорт в придомовой территории
• Поставщики будут действовать в соответствии со своими общими обязательствами по поддержке организации в случае стихийного бедствия
Этот список допущений не является исчерпывающим, но предназначен для размышлений на начальном этапе планирования.
Сами предположения часто определяют состав плана; следовательно, руководство должно тщательно проанализировать их на предмет уместности.
Групповой подход
Структура организации на случай непредвиденных обстоятельств может не совпадать с существующей организационной схемой.
Командный подход используется при разработке плана, а также при восстановлении после аварии. Команды имеют определенные обязанности и обеспечивают плавное восстановление.
В каждой команде должны быть назначены менеджер и заместитель. Эти лица обеспечивают необходимое руководство и направление при разработке разделов плана и выполнении обязанностей во время стихийного бедствия.
Потенциальные группы включают:
• Группа управления
• Группа восстановления бизнеса
• Группа восстановления отдела
• Группа восстановления компьютеров
• Группа оценки повреждений
• Группа безопасности
• Группа поддержки объектов
• Группа административной поддержки
• Группа поддержки логистики
• Группа поддержки пользователей
• Группа резервного копирования компьютеров
• Группа удаленного хранения
• Группа программного обеспечения
• Группа связи
• Группа приложений
• Группа восстановления компьютеров
• Группа по связям с общественностью
• Группа по маркетингу/отношению с клиентами
• Другие группы
Возможны различные комбинации вышеперечисленных групп в зависимости от размера и требований организации. Количество членов, закрепленных за конкретной командой, также может варьироваться в зависимости от необходимости.
Резюме
Преимущества эффективных процедур аварийного восстановления включают:
• Устранение путаницы и ошибок
• Предоставление обучающих материалов для новых сотрудников
• Снижение зависимости от определенных ключевых лиц и функций
В следующем выпуске третья часть в этой серии будут описаны конкретные методы и материалы, которые могут ускорить процесс сбора данных.
Это третья часть серии, в которой описываются конкретные методы организации и написания комплексного плана аварийного восстановления. В первой части этой серии описан процесс разработки подробного плана аварийного восстановления. Во второй статье описаны конкретные методы организации и написания комплексного плана аварийного восстановления. В этой статье представлены конкретные методы и материалы, которые могут ускорить процесс сбора данных.
Аварийное восстановление — это забота всей организации, а не только обработки данных. Для разработки эффективного плана должны быть задействованы все отделы. Во всех отделах должны быть определены критические потребности. Критические потребности включают в себя всю информацию и оборудование, необходимые для продолжения работы, если отделение будет уничтожено или станет недоступным.
ОПРЕДЕЛЕНИЕ ОСНОВНЫХ ПОТРЕБНОСТЕЙ
Для определения основных потребностей организации каждый отдел должен документировать все функции, выполняемые в рамках этого отдела. Анализ за период от двух недель до одного месяца может указать на основные функции, выполняемые внутри и за пределами отдела, и помочь в определении необходимых данных, необходимых отделу для удовлетворительного выполнения его повседневных операций. Некоторые из диагностических вопросов, которые можно задать, включают:
1. Если произойдет бедствие, как долго отделение сможет функционировать без существующего оборудования и ведомственной организации?
2. Каковы задачи с высоким приоритетом, включая критические ручные функции и процессы в отделе? Как часто выполняются эти задачи, например, ежедневно, еженедельно, ежемесячно и т. д.?
3. Какие кадры, оборудование, формы и расходные материалы потребуются для выполнения высокоприоритетных задач?
4. Как будет заменено критическое оборудование, формы и расходные материалы в случае стихийного бедствия?
5. Требует ли какая-либо из приведенной выше информации длительных сроков замены?
6. Какие справочники и инструкции по эксплуатации используются в отделении? Как их заменить в случае аварии?
7. Должны ли какие-либо формы, расходные материалы, оборудование, инструкции по процедурам или справочные руководства из отдела храниться за пределами офиса?
8. Определить хранение и безопасность оригиналов документов. Как эта информация будет заменена в случае бедствия? Должна ли эта информация находиться в более защищенном месте?
9. Каковы текущие процедуры резервного копирования микрокомпьютеров? Бэкапы восстановились? Должны ли какие-либо важные резервные копии храниться вне офиса?
10. Какими будут временные рабочие процедуры в случае стихийного бедствия?
11. Как прерывание работы отдела повлияет на другие отделы?
12.Как авария на главном компьютере повлияет на отдел?
13. Какие внешние службы/поставщики используются для нормальной работы?
14. Может ли катастрофа в отделении поставить под угрозу какие-либо юридические требования к отчетности?
15. Имеются ли должностные инструкции и актуальны ли они для отдела?
16. Проходит ли персонал отдела перекрестное обучение?
17. Кто будет нести ответственность за выполнение плана действий отдела в чрезвычайных ситуациях?
18. Есть ли другие проблемы, связанные с планированием аварийного восстановления?
Критические потребности могут быть последовательно получены с помощью Анкеты отдела пользователей. Как показано, анкета направлена на документирование важнейших видов деятельности в каждом отделе и определение соответствующих минимальных требований к персоналу, оборудованию, бланкам, расходным материалам, документации, помещениям и другим ресурсам.
УСТАНОВКА ПРИОРИТЕТОВ ОБРАБОТКИ И ОПЕРАЦИЙ
После документирования критических потребностей руководство может установить приоритеты в отделах для общего восстановления организации. Деятельности каждого отдела можно было бы присвоить приоритеты следующим образом
• Основные виды деятельности – Перебои в обслуживании более чем на один день серьезно поставят под угрозу работу организации.
• Рекомендуемые действия – перерыв в обслуживании более чем на одну неделю серьезно поставит под угрозу работу организации.
• Второстепенные виды деятельности – Эту информацию было бы удобно иметь, но она не будет серьезно умалять эксплуатационные возможности в случае ее отсутствия.
СОХРАНЕНИЕ ЗАПИСЕЙ
РЕКОМЕНДАЦИИ
Систематический подход к управлению записями является важной частью комплексного плана аварийного восстановления. Дополнительные преимущества:
• Снижение затрат на хранение.
• Ускоренное обслуживание клиентов.
• Соответствие федеральным и государственным нормативным требованиям.
Записи хранятся не только в качестве доказательства финансовых транзакций, но и для проверки соблюдения законодательных и нормативных требований. Кроме того, предприятия должны соответствовать требованиям удержания как организация и работодатель. Эти записи используются для независимой проверки и проверки надлежащей деловой практики. Федеральные требования и требования штата по хранению документации должны анализироваться каждой организацией индивидуально. Каждая организация должна иметь своего юрисконсульта для утверждения собственного графика хранения.
Помимо хранения записей, организация должна быть осведомлена о конкретных методах и процедурах спасения записей, которым необходимо следовать для различных типов носителей. К возможным типам носителей относятся:
• Бумага
• Магнитная
• Микрофильм/микрофиша
• Изображение
• Фото
• Другое
Инвентаризация оборудования для документирования всего критически важного оборудования, необходимого организации. Если время восстановления превышает допустимое, следует рассмотреть альтернативу резервного копирования.
• Основной список поставщиков для определения поставщиков, которые предоставляют критически важные товары и услуги.
• Инвентаризация канцелярских принадлежностей для регистрации важнейших канцелярских принадлежностей для облегчения их замены. Если товар имеет более длительный срок поставки, чем это допустимо, большее количество должно храниться за пределами площадки.
• Инвентарный список форм для документирования всех форм, используемых организацией, для облегчения замены. Этот список должен включать компьютерные формы и некомпьютерные формы.
• Инвентарный список документации для записи инвентарного списка важнейших руководств и материалов по документации. Важно определить, доступны ли резервные копии критической документации. Они могут быть сохранены на диске, получены из филиалов, доступны из внешних источников, поставщиков и других источников.
• Важные телефонные номера, чтобы перечислить важные телефонные номера, контактные имена и конкретные услуги для организаций и поставщиков, важных для процесса восстановления.
• Контрольный список уведомлений для документирования обязанностей по уведомлению персонала, поставщиков и других сторон. Каждой команде должны быть назначены определенные стороны для контакта.
• Основной список вызовов для документирования телефонных номеров сотрудников.
• Список резервных должностей для определения резервных сотрудников на каждой критической должности в организации. Определенный ключевой персонал может быть недоступен в случае стихийного бедствия; следовательно, необходимо определить резервные копии для каждой критической позиции.
• Спецификации для удаленного местоположения для документирования желаемых/требуемых спецификаций возможного альтернативного местоположения для каждого существующего местоположения.
• Инвентаризация мест хранения за пределами площадки для документирования всех материалов, хранящихся за пределами площадки.
• Инвентаризационный список аппаратного и программного обеспечения для документирования инвентарного списка аппаратного и программного обеспечения.
• Инвентарный список телефонов для документирования существующих телефонных систем, используемых организацией.
• Список страховых полисов для документирования действующих страховых полисов.
• Инвентарный список средств связи для документирования всех компонентов сети связи.
Существует несколько систем планирования аварийного восстановления на базе ПК, которые можно использовать для облегчения процесса сбора данных и разработки плана. Как правило, в этих системах упор делается либо на приложение базы данных, либо на приложение для обработки текстов. Наиболее комплексные системы используют комбинацию интегрированных приложений.
Некоторые компьютерные системы содержат образец плана, который можно адаптировать к уникальным требованиям каждой организации. Другие материалы могут включать инструкции, касающиеся проблем, связанных с аварийным восстановлением, которые организация должна учитывать в процессе планирования, таких как предотвращение аварий, страховой анализ, сохранение записей и стратегии резервного копирования. Специализированные консультации также могут быть доступны с системой для обеспечения установки на месте, обучения и консультирования по различным вопросам планирования аварийного восстановления.
Преимущества использования системы на базе ПК для разработки плана аварийного восстановления включают:
• Системный подход к процессу планирования.
• Предварительно разработанные методики.
• Эффективный метод технического обслуживания.
• Значительное сокращение времени и усилий в процессе планирования и разработки.
• Проверенный метод.
Недавно были разработаны другие инструменты для ПК, помогающие в этом процессе, в том числе обучающие системы по планированию аварийного восстановления и программное обеспечение для облегчения процесса тестирования.
ЗАКЛЮЧЕНИЕ
Планирование аварийного восстановления включает в себя нечто большее, чем внешнее хранение или обработку резервных копий. Организации также должны разработать письменные комплексные планы аварийного восстановления, которые охватывают все критически важные операции и функции бизнеса. План должен включать задокументированные и проверенные процедуры, соблюдение которых обеспечит постоянную доступность критически важных ресурсов и непрерывность операций.
К преимуществам разработки комплексного плана аварийного восстановления относятся:
• Минимизация потенциальных экономических потерь.
• Снижение потенциального воздействия.
• Снижение вероятности возникновения.
• Сокращение перерывов в работе.
• Обеспечение организационной стабильности.
• Обеспечение упорядоченного восстановления.
• Минимизация страховых взносов.
• Снижение зависимости от некоторых ключевых лиц.
• Защита активов организации.
• Обеспечение безопасности персонала и клиентов.
• Сведение к минимуму принятия решений во время стихийного бедствия.
• Минимизация юридической ответственности.
Джеффри Х. Уолд — национальный директор по информационным системам и технологическому консалтингу CPA/консалтинговой фирмы McGladrey & Pullen. Он написал четыре книги по планированию аварийного восстановления.
Архитектура аварийного восстановления Azure для Azure в Azure Site Recovery — Azure Site Recovery
- Статья
- 10 минут на чтение
В этой статье описываются архитектура, компоненты и процессы, используемые при развертывании аварийного восстановления для виртуальных машин Azure с помощью службы Azure Site Recovery. После настройки аварийного восстановления виртуальные машины Azure непрерывно реплицируются в другой целевой регион. В случае сбоя вы можете выполнить аварийное переключение виртуальных машин в дополнительный регион и получить к ним доступ оттуда. Когда все снова заработает нормально, вы сможете вернуться к исходному состоянию и продолжить работу в основном расположении.
Архитектурные компоненты
Компоненты, участвующие в аварийном восстановлении виртуальных машин Azure, перечислены в следующей таблице.
Виртуальные машины
| Компонент | Требования |
|---|---|
| ВМ в исходном регионе | Одна или несколько виртуальных машин Azure в поддерживаемом исходном регионе. Виртуальные машины могут работать под управлением любой поддерживаемой операционной системы. |
| Хранилище исходной ВМ | Виртуальные машины Azure могут быть управляемыми или иметь неуправляемые диски, распределенные по учетным записям хранения. Узнайте о поддерживаемом хранилище Azure. |
| Исходные сети виртуальных машин | могут находиться в одной или нескольких подсетях виртуальной сети (VNet) в исходном регионе. Узнайте больше о требованиях к сети. |
| Учетная запись хранения кэша | Вам нужна учетная запись хранения кэша в исходной сети. Во время репликации изменения ВМ сохраняются в кеше перед отправкой в целевое хранилище. Учетные записи хранения кэша должны быть стандартными. Использование кэша обеспечивает минимальное влияние на производственные приложения, работающие на виртуальной машине. Узнайте больше о требованиях к объему кэш-памяти. |
| Целевые ресурсы | Целевые ресурсы используются во время репликации и при отработке отказа. Site Recovery может настроить целевой ресурс по умолчанию, или вы можете создать/настроить их. В целевом регионе убедитесь, что вы можете создавать виртуальные машины и что в вашей подписке достаточно ресурсов для поддержки размеров виртуальных машин, которые потребуются в целевом регионе. |
Целевые ресурсы
При включении репликации для виртуальной машины Site Recovery дает возможность автоматически создавать целевые ресурсы.
| Целевой ресурс | Настройка по умолчанию |
|---|---|
| Целевая подписка | То же, что и исходная подписка. |
| Целевая группа ресурсов | : Группа ресурсов, к которой принадлежат виртуальные машины после отработки отказа. Может находиться в любом регионе Azure, кроме исходного региона. Site Recovery создает новую группу ресурсов в целевом регионе с суффиксом «asr». |
| Целевая виртуальная сеть | Виртуальная сеть (VNet), в которой находятся реплицированные виртуальные машины после отработки отказа. Сетевое сопоставление создается между исходной и целевой виртуальными сетями и наоборот. Site Recovery создает новую виртуальную сеть и подсеть с суффиксом asr. |
| Целевая учетная запись хранения | Если виртуальная машина не использует управляемый диск, это учетная запись хранения, в которую реплицируются данные. Site Recovery создает новую учетную запись хранения в целевом регионе для зеркального отображения исходной учетной записи хранения. |
| Реплики управляемых дисков | Если виртуальная машина использует управляемый диск, это управляемые диски, на которые реплицируются данные. Site Recovery создает реплики управляемых дисков в области хранения для зеркалирования источника. |
| Целевые наборы доступности | Набор доступности, в котором находятся реплицированные ВМ после отработки отказа. Site Recovery создает группу доступности в целевом регионе с суффиксом «asr» для виртуальных машин, находящихся в группе доступности в исходном расположении. Если группа доступности существует, она используется, а новая не создается. |
| Целевые зоны доступности | Если целевой регион поддерживает зоны доступности, Site Recovery назначает тот же номер зоны, что и исходный регион. |
Управление целевыми ресурсами
Вы можете управлять целевыми ресурсами следующим образом:
- Вы можете изменять целевые параметры при включении репликации. Обратите внимание, что номер SKU по умолчанию для виртуальной машины целевого региона совпадает с номером SKU исходной виртуальной машины (или следующим лучшим доступным номером SKU по сравнению с номером SKU исходной виртуальной машины). В раскрывающемся списке отображаются только соответствующие SKU того же семейства, что и исходная виртуальная машина (Gen 1 или Gen 2).
- Вы можете изменить настройки цели после того, как репликация уже работает. Подобно другим ресурсам, таким как целевая группа ресурсов, целевое имя и другие, номер SKU виртуальной машины целевого региона также можно обновить после выполнения репликации. Ресурс, который не может быть обновлен, относится к типу доступности (отдельный экземпляр, набор или зона). Чтобы изменить этот параметр, необходимо отключить репликацию, изменить параметр, а затем снова включить.
Политика репликации
При включении репликации виртуальных машин Azure Site Recovery по умолчанию создает новую политику репликации с параметрами по умолчанию, приведенными в таблице.
| Настройка политики | Детали | По умолчанию |
|---|---|---|
| Сохранение точки восстановления | Указывает, как долго Site Recovery хранит точки восстановления. | 1 день |
| Частота моментальных снимков приложений | Как часто Site Recovery делает моментальный снимок, согласованный с приложением. | 0 часов (отключено) |
Управление политиками репликации
Вы можете управлять и изменять параметры политик репликации по умолчанию следующим образом:
- Вы можете изменять параметры при включении репликации.
- Вы можете создать политику репликации в любое время, а затем применить ее при включении репликации.
Примечание
Длительный срок хранения точек восстановления может повлиять на стоимость хранилища, поскольку может потребоваться сохранение большего количества точек восстановления.
Согласованность нескольких виртуальных машин
Если вы хотите, чтобы виртуальные машины реплицировались вместе и имели общие точки восстановления, устойчивые к сбоям и приложениям, при отработке отказа, вы можете собрать их вместе в группу репликации. Согласованность нескольких виртуальных машин влияет на производительность рабочей нагрузки и должна использоваться только для виртуальных машин, выполняющих рабочие нагрузки, которым требуется согласованность на всех машинах.
Моментальные снимки и точки восстановления
Точки восстановления создаются из моментальных снимков дисков ВМ, сделанных в определенный момент времени. При отработке отказа виртуальной машины вы используете точку восстановления для восстановления виртуальной машины в целевом расположении.
При отработке отказа мы обычно хотим убедиться, что виртуальная машина запускается без повреждения или потери данных и что данные виртуальной машины непротиворечивы для операционной системы и приложений, работающих на виртуальной машине. Это зависит от типа сделанных снимков.
Site Recovery делает снимки следующим образом:
- Site Recovery по умолчанию создает устойчивые к сбоям моментальные снимки данных и моментальные снимки, согласованные с приложениями, если вы укажете для них периодичность.
- Точки восстановления создаются из моментальных снимков и сохраняются в соответствии с параметрами хранения в политике репликации.
Согласованность
В следующей таблице описаны различные типы согласованности.
Устойчивость к сбоям
| Описание | Детали | Рекомендация |
|---|---|---|
| Устойчивый к сбоям моментальный снимок захватывает данные, которые были на диске в момент создания моментального снимка. Он ничего не включает в память. Он содержит эквивалент данных на диске, которые были бы представлены в случае сбоя виртуальной машины или отключения кабеля питания от сервера в момент создания моментального снимка. Устойчивость к сбоям не гарантирует согласованность данных для операционной системы или приложений на виртуальной машине. | Site Recovery по умолчанию создает устойчивые к сбоям точки восстановления каждые пять минут. Этот параметр нельзя изменить. | Сегодня большинство приложений могут хорошо восстанавливаться после аварийных ситуаций. Устойчивых к сбоям точек восстановления обычно достаточно для репликации операционных систем и приложений, таких как DHCP-серверы и серверы печати. |
Совместимость с приложением
| Описание | Детали | Рекомендация |
|---|---|---|
| Точки восстановления, согласованные с приложениями, создаются из моментальных снимков, согласованных с приложениями. Моментальный снимок, согласованный с приложением, содержит всю информацию из моментального снимка, согласованного с приложением, а также все данные в памяти и выполняемые транзакции. | Моментальные снимки, согласованные с приложением, используют службу теневого копирования томов (VSS): 1) Azure Site Recovery использует метод резервного копирования только для копирования (VSS_BT_COPY), который не изменяет время резервного копирования журнала транзакций Microsoft SQL и порядковый номер 2) Когда моментальный снимок инициируется, VSS выполняет операцию копирования при записи (COW) на томе. 3) Прежде чем выполнять COW, VSS информирует каждое приложение на компьютере о том, что ему необходимо сбросить данные, находящиеся в памяти, на диск. 4) Затем VSS позволяет приложению резервного копирования/аварийного восстановления (в данном случае Site Recovery) прочитать данные снимка и продолжить работу. | Снимки, согласованные с приложением, создаются с указанной вами периодичностью. Эта частота всегда должна быть меньше, чем вы установили для сохранения точек восстановления. Например, если вы сохраняете точки восстановления, используя параметр по умолчанию, равный 24 часам, вам следует установить периодичность менее 24 часов. Они более сложны и занимают больше времени, чем устойчивые к сбоям моментальные снимки. Они влияют на производительность приложений, работающих на виртуальной машине, для которой включена репликация. |
Процесс репликации
При включении репликации для виртуальной машины Azure происходит следующее:
- Расширение службы Site Recovery Mobility автоматически устанавливается на виртуальной машине.
- Расширение регистрирует виртуальную машину в Site Recovery.
- Начинается непрерывная репликация виртуальной машины. Записи на диск немедленно передаются в учетную запись хранения кэша в исходном расположении.
- Site Recovery обрабатывает данные в кэше и отправляет их в целевую учетную запись хранения или на управляемые диски реплики.
- После обработки данных критически устойчивые точки восстановления создаются каждые пять минут. Согласованные с приложениями точки восстановления создаются в соответствии с параметром, указанным в политике репликации.
Процесс репликации
Требования к подключению
Виртуальные машины Azure, которые вы реплицируете, нуждаются в исходящем подключении. Site Recovery никогда не требует входящего подключения к виртуальной машине.
Исходящие подключения (URL-адреса)
Если исходящий доступ для виртуальных машин контролируется с помощью URL-адресов, разрешите эти URL-адреса.
| Имя | Коммерческий | Правительство | Описание |
|---|---|---|---|
| Хранение | *.blob.core.windows.net | *.blob.core.usgovcloudapi.net | Позволяет записывать данные с виртуальной машины в учетную запись хранения кэша в исходном регионе. |
| Azure Active Directory | логин.микрософтонлайн.com | логин.microsoftonline.us | Обеспечивает авторизацию и проверку подлинности для URL-адресов службы восстановления сайта. |
| Репликация | *.hypervrecoverymanager.windowsazure.com | *.hypervrecoverymanager.windowsazure.com | Позволяет виртуальной машине обмениваться данными со службой восстановления сайта. |
| Служебный автобус | *.servicebus.windows.net | *.servicebus.usgovcloudapi.net | Позволяет виртуальной машине записывать данные мониторинга и диагностики Site Recovery. |
| Хранилище ключей | *.vault.azure.net | *.vault.usgovcloudapi.net | Разрешает доступ для включения репликации виртуальных машин с поддержкой ADE через портал |
| Автоматизация Azure | *. | *.azure-automation.us | Позволяет включить автоматическое обновление агента мобильности для реплицированного элемента через портал |
Исходящие подключения для диапазонов IP-адресов
Чтобы управлять исходящими подключениями для виртуальных машин, использующих IP-адреса, разрешите эти адреса.
Обратите внимание, что подробные сведения о требованиях к сетевому подключению можно найти в официальном документе по сети
Правила исходного региона
| Правило | Детали | Сервисная бирка |
|---|---|---|
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие учетным записям хранения в исходном регионе | Хранилище.<имя-региона> |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure Active Directory (Azure AD) | Азуреактиведиректори |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие концентратору событий в целевом регионе. | EventHub.<имя-региона> |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure Site Recovery | Азуриситерековери |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure Key Vault (требуется только для включения репликации виртуальных машин с поддержкой ADE через портал) | AzureKeyVault |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие контроллеру автоматизации Azure (это требуется только для включения автоматического обновления агента мобильности для реплицированного элемента через портал) | Гестандгибридманажемент |
Правила целевого региона
.
| Правило | Детали | Сервисная бирка |
|---|---|---|
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие учетным записям хранения в целевом регионе | Хранилище. <имя-региона> |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure AD | Азуреактиведиректори |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие концентратору событий в исходном регионе. | EventHub.<имя-региона> |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure Site Recovery | Азуриситерековери |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие Azure Key Vault (это требуется только для включения репликации виртуальных машин с поддержкой ADE через портал) | AzureKeyVault |
| Разрешить исходящий HTTPS: порт 443 | Разрешить диапазоны, соответствующие контроллеру автоматизации Azure (требуется только для включения автоматического обновления агента мобильности для реплицированного элемента через портал) | Гестандгибридманажемент |
Управление доступом с помощью правил NSG
Если вы управляете подключением виртуальных машин, фильтруя сетевой трафик в сети и подсети Azure с помощью правил NSG, обратите внимание на следующие требования:
- Правила NSG для исходного региона Azure должны разрешать исходящий доступ для трафика репликации.
- Мы рекомендуем создавать правила в тестовой среде, прежде чем запускать их в рабочую среду.
- Используйте служебные теги вместо разрешения отдельных IP-адресов.
- Служебные теги представляют собой группу префиксов IP-адресов, собранных вместе для минимизации сложности при создании правил безопасности.
- Microsoft автоматически обновляет теги обслуживания с течением времени.
Узнайте больше об исходящих подключениях для Site Recovery и управлении подключением с помощью групп безопасности сети.
Возможность подключения для согласованности нескольких виртуальных машин
Если вы включите согласованность нескольких виртуальных машин, машины в группе репликации взаимодействуют друг с другом через порт 20004.
- Убедитесь, что брандмауэр не блокирует внутреннюю связь между виртуальными машинами через порт 20004.
- Если вы хотите, чтобы виртуальные машины Linux были частью группы репликации, убедитесь, что исходящий трафик через порт 20004 открыт вручную в соответствии с рекомендациями для конкретной версии Linux.
Процесс отработки отказа
При запуске отработки отказа виртуальные машины создаются в целевой группе ресурсов, целевой виртуальной сети, целевой подсети и целевой группе доступности. Во время отработки отказа вы можете использовать любую точку восстановления.
Следующие шаги
Быстро реплицируйте виртуальную машину Azure в дополнительный регион.
Варианты аварийного восстановления в облаке
Стратегии аварийного восстановления, доступные вам в AWS, можно в общих чертах разделить на
четыре подхода, начиная от низкой стоимости и низкой сложности создания резервных копий и заканчивая более сложными
стратегии с использованием нескольких активных регионов. Активные/пассивные стратегии используют активный сайт (например,
регион AWS) для размещения рабочей нагрузки и обслуживания трафика. Пассивный сайт (например, другой AWS
Регион) используется для восстановления. Пассивный сайт не обслуживает активно трафик до аварийного переключения.
событие срабатывает.
Крайне важно регулярно оценивать и тестировать стратегию аварийного восстановления, чтобы
иметь уверенность в вызове его, если это станет необходимым. Используйте AWS Resilience Hub для постоянной проверки и отслеживания
устойчивость ваших рабочих нагрузок AWS, в том числе вероятность того, что вы достигнете своих RTO и RPO
цели.
Рисунок 6 – Стратегии аварийного восстановления
В случае стихийного бедствия, связанного с нарушением или потерей одного физического
дата-центр для
хорошо спроектированный,
высокодоступная рабочая нагрузка, вам может потребоваться только резервное копирование и восстановление
подход к аварийному восстановлению. Если ваше определение бедствия идет
помимо нарушения или потери физического центра обработки данных до
регионе или если вы подпадаете под действие нормативных требований, требующих
это, то вы должны рассмотреть Pilot Light, Warm Standby или
Многосайтовый активный/активный.
При выборе стратегии и ресурсов AWS для ее реализации помните, что в пределах
AWS мы обычно делим сервисы на плоскость данных и
плоскость управления . Плоскость данных отвечает за доставку в режиме реального времени.
службы, в то время как плоскости управления используются для настройки среды. Для максимальной отказоустойчивости вы
следует использовать только операции с плоскостью данных как часть операции аварийного переключения. Это потому, что
плоскости данных обычно имеют более высокие цели проектирования доступности, чем плоскости управления.
Резервное копирование и восстановление
Резервное копирование и восстановление — это подходящий подход для предотвращения потери или повреждения данных.
Этот подход также можно использовать для смягчения последствий региональной катастрофы путем репликации данных на
других регионах AWS или для устранения недостатка избыточности рабочих нагрузок, развернутых в одном
Зона доступности. Помимо данных, вы должны повторно развернуть инфраструктуру, конфигурацию,
и код приложения в области восстановления. Чтобы обеспечить быстрое перераспределение инфраструктуры
без ошибок всегда следует развертывать с использованием инфраструктуры как кода (IaC) с использованием сервисов
таких как AWS CloudFormation или AWS Cloud Development Kit (AWS CDK). Без IaC может быть сложно восстановить рабочие нагрузки в
регион восстановления, что приведет к увеличению времени восстановления и, возможно, к превышению вашего RTO. В
в дополнение к пользовательским данным обязательно сделайте резервную копию кода и конфигурации, включая образы машин Amazon.
(AMI), которые вы используете для создания инстансов Amazon EC2. Вы можете использовать AWS CodePipeline для автоматизации повторного развертывания кода приложения и
конфигурация.
Рис. 7. Архитектура резервного копирования и восстановления
Сервисы AWS
Для данных вашей рабочей нагрузки потребуется стратегия резервного копирования, которая работает
периодически или непрерывно. Как часто вы запускаете резервное копирование
определит вашу достижимую точку восстановления (которая должна
выровняйте, чтобы соответствовать вашему RPO). Резервная копия также должна предлагать способ
восстановить его до момента времени, когда он был взят. Резервное копирование
с восстановлением на момент времени доступно через следующие
услуги и ресурсы:
Для Amazon Simple Storage Service (Amazon S3) вы можете использовать
Межрегиональная репликация Amazon S3 (CRR) для асинхронного копирования
объекты в корзину S3 в области аварийного восстановления постоянно, в то время как
предоставление версий для хранимых объектов, чтобы вы могли
выберите точку восстановления. Непрерывная репликация данных
имеет преимущество в кратчайшем времени (почти нулевом) возврата
ваши данные, но может не защитить от аварийных событий, таких как
как повреждение данных или злонамеренная атака (например, несанкционированное
удаление данных), а также резервное копирование на определенный момент времени. Непрерывный
репликация покрывается в AWS
Услуги для пилотной секции.
AWS Backup предоставляет централизованное место для настройки,
планировать и отслеживать возможности резервного копирования AWS для следующих
услуги и ресурсы:
AWS Backup поддерживает копирование резервных копий между регионами, например в
Регион аварийного восстановления.
В качестве дополнительной стратегии аварийного восстановления для вашего Amazon S3
данные, включить
S3
версионность объекта. Управление версиями объектов защищает ваши данные
в S3 от последствий действий по удалению или модификации
сохраняя исходную версию перед действием. Объект
управление версиями может быть полезным средством смягчения последствий человеческой ошибки.
бедствия. Если вы используете репликацию S3 для резервного копирования данных на
вашего региона DR, то по умолчанию при удалении объекта в
исходное ведро,
Amazon S3 добавляет маркер удаления только в исходную корзину. Этот
подход защищает данные в регионе аварийного восстановления от злонамеренного удаления
в исходном регионе.
В дополнение к данным, вы также должны сделать резервную копию конфигурации и
инфраструктура, необходимая для перераспределения вашей рабочей нагрузки и удовлетворения ваших
Целевое время восстановления (RTO).
AWS CloudFormation предоставляет инфраструктуру как код (IaC) и
позволяет вам определить все ресурсы AWS в вашей рабочей нагрузке
поэтому вы можете надежно развертывать и повторно развертывать несколько учетных записей AWS.
и регионы AWS. Вы можете создавать резервные копии инстансов Amazon EC2, используемых
вашу рабочую нагрузку в виде образов машин Amazon (AMI). AMI это
созданные из моментальных снимков корневого тома вашего экземпляра и любых
другие тома EBS, подключенные к вашему экземпляру. Вы можете использовать это
AMI для запуска восстановленной версии инстанса EC2. Ан
АМИ
могут быть скопированы внутри или между регионами. Или вы можете использовать
AWS Backup для копирования резервных копий между учетными записями и на другие AWS
Регионы. Возможность резервного копирования между учетными записями помогает защитить
стихийные бедствия, которые включают внутренние угрозы или учетную запись
компромисс. AWS Backup также добавляет дополнительные возможности для EC2.
резервное копирование — помимо отдельных томов EBS экземпляра, AWS Backup также хранит и отслеживает следующие метаданные: экземпляр
тип, настроенное виртуальное частное облако (VPC), группа безопасности,
Я
роль, конфигурацию мониторинга и теги. Однако это
дополнительные метаданные используются только при восстановлении резервной копии EC2
в тот же регион AWS.
Любые данные, хранящиеся в регионе аварийного восстановления в качестве резервных копий, должны быть восстановлены во время
отказоустойчивость. AWS Backup предлагает возможность восстановления, но в настоящее время не включает запланированные или
автоматическое восстановление. Вы можете реализовать автоматическое восстановление в регион аварийного восстановления с помощью AWS
SDK для вызова API для AWS Backup. Вы можете настроить это как регулярно повторяющееся задание или триггер
восстановление после завершения резервного копирования. На следующем рисунке показан пример
автоматическое восстановление с помощью Amazon Simple Notification Service (Amazon SNS) и
АВС Лямбда. Осуществление планового периодического
восстановление данных — хорошая идея, поскольку восстановление данных из резервной копии — это операция уровня управления. Если
эта операция была недоступна во время стихийного бедствия, у вас все еще были бы работоспособные данные
хранилища, созданные из последней резервной копии.
Рис. 8. Восстановление и проверка резервных копий
Примечание
Ваша стратегия резервного копирования должна включать проверку резервных копий. Дополнительные сведения см. в разделе «Тестирование аварийного восстановления».
информация. См. практическое руководство в лаборатории AWS Well-Architected: Testing Backup and Restore of Data.
демонстрация реализации.
Сигнальная лампа
С подходом пилотного света вы копируете
ваши данные из одного региона в другой и предоставить копию вашего
основная инфраструктура рабочей нагрузки. Ресурсы, необходимые для поддержки данных
репликация и резервное копирование, такие как базы данных и хранилище объектов,
всегда включен. Другие элементы, такие как серверы приложений, загружаются
с кодом приложения и конфигурациями, но «выключены» и
используются только во время тестирования или при отказоустойчивости аварийного восстановления.
вызывается. В облаке у вас есть возможность деинициализировать ресурсы
когда они вам не нужны, и подготовьте их, когда они вам понадобятся. Лучшей практикой для «выключено» является
не развертывать ресурс, а затем создать конфигурацию и возможности для его развертывания («включить»)
при необходимости.
В отличие от подхода резервного копирования и восстановления, ваш основной
инфраструктура всегда доступна, и у вас всегда есть возможность
быстро подготовить полномасштабную производственную среду,
включение и масштабирование серверов приложений.
Рисунок 9. Архитектура пилотной лампы
Подход с пилотным светом сводит к минимуму текущие расходы на случай стихийного бедствия
восстановление за счет минимизации активных ресурсов и упрощения
восстановление во время аварии, поскольку основная инфраструктура
требования все на месте. Этот вариант восстановления требует от вас
чтобы изменить подход к развертыванию. Вам нужно сделать ядро
изменения инфраструктуры в каждом регионе и развертывание рабочей нагрузки
(конфигурация, код) изменяется одновременно для каждого региона. Этот
шаг можно упростить, автоматизировав развертывание и используя
инфраструктура как код (IaC) для развертывания инфраструктуры в
несколько учетных записей и регионов (полное развертывание инфраструктуры в
основной Регион и уменьшенная/отключенная инфраструктура
развертывание в регионах DR). Рекомендуется использовать другой
учетная запись для каждого региона, чтобы обеспечить наивысший уровень ресурсов и
изоляция безопасности (в случае, если скомпрометированные учетные данные являются частью
ваших планов аварийного восстановления).
При таком подходе вы также должны смягчить
катастрофа. Непрерывная репликация данных защищает вас от некоторых
типы бедствий, но это может не защитить вас от данных
коррупции или уничтожения, если только ваша стратегия не включает
управление версиями хранимых данных или варианты восстановления на определенный момент времени.
Вы можете создать резервную копию реплицированных данных в регионе бедствия, чтобы
создавать резервные копии на определенный момент времени в том же регионе.
Сервисы AWS
Помимо использования сервисов AWS, описанных в
Резервное копирование и восстановление
раздел для создания резервных копий на определенный момент времени, также учитывайте
следующие услуги для вашей стратегии пилотного света.
Для пилотного проекта непрерывная репликация данных в действующие базы данных
и хранилища данных в регионе DR — лучший подход для низких
RPO (при использовании в дополнение к резервным копиям на момент времени
обсуждалось ранее). AWS обеспечивает непрерывную межрегиональную
асинхронная репликация данных для данных с использованием следующих
услуги и ресурсы:
При непрерывной репликации версии ваших данных становятся доступными почти сразу в
ваш регион ДР. Фактическое время репликации можно отслеживать с помощью сервисных функций, таких как S3.
Контроль времени репликации (S3 RTC) для объектов и управления S3
возможности глобальных баз данных Amazon Aurora.
При сбое для выполнения рабочей нагрузки чтения/записи из
регион аварийного восстановления, вы должны продвигать реплику чтения RDS
стать основным экземпляром. Для
БД
экземпляров, кроме Aurora, процесс занимает несколько
минут для завершения, и перезагрузка является частью процесса. Для
Межрегиональная репликация (CRR) и отработка отказа с помощью RDS с использованием
Глобальная база данных Amazon Aurora имеет ряд преимуществ.
Глобальная база данных использует выделенную инфраструктуру, которая оставляет
базы данных, полностью доступные для обслуживания вашего приложения, и могут
реплицировать во вторичный регион с типичной задержкой менее
в секунду (а в пределах региона AWS намного меньше 100
миллисекунды). С глобальной базой данных Amazon Aurora, если вы
основной регион страдает от снижения производительности или сбоя, вы
может продвигать один из вторичных регионов для чтения/записи
обязанности менее чем за одну минуту даже в случае
полное региональное отключение. Вы также можете настроить
Aurora для мониторинга времени задержки RPO всех вторичных кластеров, чтобы убедиться, что хотя бы один вторичный
кластер остается в пределах целевого окна RPO.
Уменьшенная версия вашей основной инфраструктуры рабочей нагрузки с меньшим или меньшим
ресурсы должны быть развернуты в вашем регионе аварийного восстановления. Используя AWS CloudFormation, вы можете определить
инфраструктуру и последовательно развертывайте ее в аккаунтах AWS и регионах AWS.
AWS CloudFormation использует предопределенные псевдо
параметры для идентификации учетной записи AWS и региона AWS, в котором она развернута.
Следовательно, вы можете реализовать логику условия
в ваших шаблонах CloudFormation, чтобы развернуть только уменьшенную версию вашего
инфраструктура в регионе ДР. Для развертываний инстансов EC2 образ машины Amazon (AMI)
предоставляет такую информацию, как конфигурация оборудования и установленное программное обеспечение. Ты можешь
внедрить построитель образов
конвейер, который создает нужные вам образы AMI и копирует их как в основной, так и в резервный
Регионы. Это помогает гарантировать, что эти золотых AMI есть все
вам необходимо повторно развернуть или масштабировать рабочую нагрузку в новом регионе в случае аварии
событие. Инстансы Amazon EC2 развернуты в уменьшенной конфигурации (меньше инстансов, чем в
ваш основной регион).
Чтобы масштабировать инфраструктуру для поддержки производственного трафика, см. раздел «Автоматическое масштабирование AWS» в разделе «Горячее резервирование».
Для активной/пассивной конфигурации, такой как контрольная лампа, весь трафик изначально идет на
основной регион и переключается на регион аварийного восстановления, если основной регион не
более доступен. Эта операция аварийного переключения может быть инициирована либо автоматически, либо вручную.
Следует использовать автоматический переход на другой ресурс на основе проверок работоспособности или сигналов тревоги.
осторожность. Даже при использовании обсуждаемых здесь передовых практик время восстановления и точка восстановления будут
быть больше нуля, что приводит к некоторой потере доступности и данных. Если вы потерпите неудачу, когда
вам не нужно (ложная тревога), то вы несете эти убытки. Инициированный вручную переход на другой ресурс
поэтому часто используется. В этом случае вам все равно следует автоматизировать шаги по переходу на другой ресурс, поэтому
что ручное инициирование похоже на нажатие кнопки.
Существует несколько вариантов управления трафиком, которые следует учитывать при использовании сервисов AWS.
Одним из вариантов является использование Amazon Route 53. Использование
Amazon Route 53, вы можете связать несколько конечных точек IP в одном или нескольких регионах AWS с Route 53.
доменное имя. Затем вы можете направить трафик в соответствующую конечную точку под этим доменным именем.
При отработке отказа вам необходимо переключить трафик на конечную точку восстановления, а не на основную
конечная точка. Проверка работоспособности Amazon Route 53 отслеживает эти конечные точки. Используя эти проверки работоспособности, вы
можно настроить автоматически инициируемую отработку отказа DNS, чтобы гарантировать отправку трафика только на исправные
конечные точки, что является высоконадежной операцией, выполняемой на уровне данных. Для реализации этого
при аварийном переключении, инициированном вручную, вы можете использовать Amazon Route 53 Application Recovery Controller. С Route 53 ARC вы
может создавать проверки работоспособности Route 53, которые на самом деле не проверяют работоспособность, а действуют как вкл/выкл
переключатели, которыми вы полностью управляете. С помощью интерфейса командной строки AWS или AWS SDK можно создавать сценарии
отказоустойчивость с помощью этого высокодоступного API плоскости данных. Ваш скрипт переключает эти переключатели
(проверки работоспособности Route 53), говорящие Route 53 направлять трафик в регион восстановления вместо
основной Регион. Другой вариант аварийного переключения, инициированный вручную, который некоторые использовали, —
используйте взвешенную политику маршрутизации и измените веса основного и резервного регионов, чтобы
что весь трафик идет в регион восстановления. Однако имейте в виду, что это плоскость управления.
и, следовательно, не так устойчив, как подход плоскости данных с использованием Amazon Route 53 Application Recovery Controller.
Другой вариант — использовать AWS Global Accelerator. Используя AnyCast IP, вы можете связать несколько конечных точек
в одном или нескольких регионах AWS с одним и тем же статическим общедоступным IP-адресом или адресами. AWS Global Accelerator затем
направляет трафик в соответствующую конечную точку, связанную с этим адресом. Проверки работоспособности Global Accelerator
контролировать конечные точки. Используя эти проверки работоспособности, AWS Global Accelerator проверяет работоспособность
приложений и автоматически направляет пользовательский трафик на исправную конечную точку приложения. Для ручного
инициированное аварийное переключение, вы можете указать, какая конечная точка получает трафик, используя набор трафика, но учтите, что это
работа плоскости управления. Global Accelerator предлагает меньшие задержки для конечной точки приложения, поскольку он
использует обширную периферийную сеть AWS для передачи трафика в магистральную сеть AWS, как только
возможный. Global Accelerator также позволяет избежать проблем с кэшированием, которые могут возникнуть в системах DNS (например, Route 53).
Amazon CloudFront предлагает аварийное переключение источника, когда в случае сбоя заданного запроса к основной конечной точке
CloudFront направляет запрос на дополнительную конечную точку. В отличие от операций аварийного переключения, описанных
ранее все последующие запросы по-прежнему направлялись к основной конечной точке, а отработка отказа выполнялась для каждого
запрос.
AWS Elastic Disaster Recovery
Эластичное аварийное восстановление AWS
(DRS) постоянно реплицирует размещенные на сервере приложения и базы данных из
любого источника в AWS, используя репликацию базового сервера на уровне блоков. Эластичный
Аварийное восстановление позволяет использовать регион в облаке AWS в качестве цели аварийного восстановления.
для рабочей нагрузки, размещенной локально или у другого облачного провайдера, и ее среды. Он может
также использоваться для аварийного восстановления рабочих нагрузок, размещенных на AWS, если они состоят только из
приложения и базы данных, размещенные на EC2 (то есть не на RDS). Elastic Disaster Recovery использует
стратегия Pilot Light, поддерживающая копию данных и «отключенных» ресурсов в
Виртуальное частное облако Amazon (Amazon VPC), используемое в качестве промежуточной зоны. Когда
событие аварийного переключения запускается, поэтапные ресурсы используются для автоматического создания
развертывание с полной емкостью в целевом Amazon VPC, используемом в качестве местоположения для восстановления.
Рис. 10. Архитектура AWS Elastic Disaster Recovery
Горячее резервирование
Подход с теплым резервированием включает в себя обеспечение
что есть уменьшенная, но полностью функциональная копия вашего
производственная среда в другом регионе. Этот подход расширяет
концепции пилотного света и сокращает время восстановления, потому что
ваша рабочая нагрузка всегда включена в другом регионе. Этот подход также
позволяет легче выполнять тестирование или реализовывать непрерывные
тестирование, чтобы повысить уверенность в своей способности оправиться от
катастрофа.
Рис. 11. Архитектура горячего резерва
Примечание: Разница между контрольным светом и теплым резервом иногда может быть
трудно понять. Оба включают среду в вашем регионе аварийного восстановления с копиями вашего
основные активы региона. Отличие в том, что пилотный свет не может обрабатывать запросы без
дополнительные действия выполняются в первую очередь, в то время как горячий резерв может обрабатывать трафик (с уменьшенной пропускной способностью).
уровни) сразу. Подход пилотного освещения требует, чтобы вы «включали» серверы, возможно
развертывание дополнительной (неосновной) инфраструктуры и масштабирование, в то время как для теплого резерва требуется только
вам масштабироваться (все уже развернуто и работает). Используйте свои RTO и RPO, чтобы
помочь вам выбрать между этими подходами.
Сервисы AWS
Все сервисы AWS, на которые распространяется резервное копирование и
восстановление и пилотный свет также используются в теплых
резервное копирование данных, репликация данных, активная/пассивная маршрутизация трафика и развертывание
инфраструктуры, включая экземпляры EC2.
AWS Auto Scaling используется для масштабирования ресурсов.
включая инстансы Amazon EC2, задачи Amazon ECS, пропускную способность Amazon DynamoDB и реплики Amazon Aurora внутри
регион AWS. Масштабирование Amazon EC2 Auto Scaling
развертывание экземпляра EC2 в зонах доступности в регионе AWS, что обеспечивает
устойчивости в этом регионе. Используйте Auto Scaling для полного масштабирования региона аварийного восстановления.
производственных мощностей, как часть стратегии пилотного освещения или теплого резерва. Например, для
EC2, увеличьте требуемая емкость настройка в группе Auto Scaling.
Вы можете настроить этот параметр вручную через Консоль управления AWS, автоматически через
SDK или путем повторного развертывания шаблона AWS CloudFormation с новым желаемым значением емкости. Ты можешь
используйте параметры AWS CloudFormation, чтобы упростить повторное развертывание шаблона CloudFormation. Гарантировать, что
услуга
квоты в вашем регионе DR установлены достаточно высокими, чтобы не ограничивать вас в масштабировании
до производственной мощности.
Поскольку Auto Scaling является действием уровня управления, зависимость от него снизит
устойчивость вашей общей стратегии восстановления. Это компромисс. Вы можете выбрать
обеспечить достаточную мощность, чтобы регион восстановления мог справиться с полным производством
загружать по мере развертывания. Эта статически стабильная конфигурация называется hot.
резервный (см. следующий раздел). Или вы можете выделить меньше ресурсов
что будет стоить меньше, но зависит от автоматического масштабирования. Некоторые реализации аварийного восстановления будут
разверните достаточно ресурсов для обработки начального трафика, обеспечив низкий RTO, а затем полагайтесь на автоматический
Масштабирование для увеличения последующего трафика.
Многосайтовый активный/активный
Вы можете запускать свою рабочую нагрузку одновременно в нескольких регионах, как
часть многосайтовой активной/активной или
горячий резерв активный/пассивный стратегия.
Multi-site active/active обслуживает трафик из всех регионов, в которые
он развернут, тогда как горячее резервирование обслуживает трафик только из
один регион, а другие регионы используются только для аварийных ситуаций
восстановление. Используя многосайтовый активный/активный подход, пользователи могут
для доступа к вашей рабочей нагрузке в любом из регионов, в которых она находится
развернут. Этот подход является наиболее сложным и дорогостоящим.
аварийное восстановление, но это может сократить время восстановления почти до
ноль для большинства бедствий при правильном выборе технологий и
реализации (однако для повреждения данных может потребоваться полагаться на
резервных копий, что обычно приводит к ненулевой точке восстановления). Горячий
в режиме ожидания используется активная/пассивная конфигурация, в которой пользователи
направляется в один регион, а регионы DR не принимают трафик.
Большинство клиентов считают, что если они собираются встать на полную
среды во втором Регионе, имеет смысл использовать его
активный / активный. В качестве альтернативы, если вы не хотите использовать оба
регионов для обработки пользовательского трафика, а теплый резерв предлагает более
экономичный и менее сложный в эксплуатации подход.
Рис. 12. Многосайтовая архитектура «активный/активный» (измените один активный путь на
Неактивен для горячего резерва)
С многосайтовым активным/активным, потому что рабочая нагрузка выполняется в
более одного региона, в этом нет такой вещи, как отказоустойчивость.
сценарий. Тестирование аварийного восстановления в этом случае будет сосредоточено на
как рабочая нагрузка реагирует на потерю региона: маршрутизируется ли трафик
подальше от несостоявшегося Региона? Может ли другой регион(ы) обрабатывать все
трафик? Также требуется тестирование на случай катастрофы данных. Резервное копирование
и восстановление по-прежнему необходимы и должны регулярно проверяться. Это
следует также отметить, что время восстановления после сбоя данных
связанные с повреждением данных, удалением или запутыванием всегда будут
больше нуля, и точка восстановления всегда будет
момент до того, как катастрофа была обнаружена. Если дополнительный
сложность и стоимость многосайтового активного/активного (или горячего резерва)
подход требуется для поддержания близкого к нулю времени восстановления, тогда
должны быть предприняты дополнительные усилия для обеспечения безопасности и
предотвращение человеческих ошибок для смягчения последствий человеческих катастроф.
Сервисы AWS
Все сервисы AWS, на которые распространяется резервное копирование и
восстановление, контрольный свет и теплый резерв также используются здесь для данных на момент времени
резервное копирование, репликация данных, активная/активная маршрутизация трафика, а также развертывание и масштабирование
инфраструктуры, включая экземпляры EC2.
Для активных/пассивных сценариев, обсуждавшихся ранее (Pilot Light
и «горячее» резервирование), как Amazon Route 53, так и AWS Global Accelerator можно использовать для маршрутизации сетевого трафика к активному
область, край. Для активной/активной стратегии здесь обе эти
службы также позволяют определять политики, определяющие
какие пользователи переходят к какой активной региональной конечной точке. С помощью AWS Global Accelerator вы устанавливаете
трафик
наберите, чтобы контролировать процент трафика, который
направлены на каждую конечную точку приложения. Amazon Route 53 поддерживает
этот процентный подход, а также
несколько
другие доступные политики, включая геоблизость и
основанные на задержке.
Global Accelerator автоматически использует обширную сеть AWS
пограничные серверы для подключения трафика к сети AWS
магистрали как можно скорее, что приводит к более низкому запросу
задержки.
Асинхронная репликация данных с этой стратегией обеспечивает почти нулевую целевую точку восстановления. АМС
такие услуги, как
Глобальная база данных Amazon Aurora использует выделенную инфраструктуру, которая
оставляет ваши базы данных полностью доступными для обслуживания ваших
приложение и может реплицироваться до пяти вторичных регионов с
типичная задержка менее секунды. С активным/пассивным
стратегии запись происходит только в основной регион.
разница с активным/активным заключается в разработке того, как согласованность данных с записью в каждый
активный регион обрабатывается. Обычно пользователь читает для
обслуживаться из ближайшего к ним региона, известного как
читать местный . При записи у вас есть несколько
параметры:
Стратегия write global маршрутизирует все
пишет в один регион. В случае отказа этого
Регион, другой регион будет повышен до принятия операций записи.
Аврора
глобальная база данных хорошо подходит для записи
global , так как поддерживает синхронизацию с
реплики чтения в регионах, и вы можете продвигать один из
вторичные регионы, чтобы взять на себя обязанности чтения/записи в
менее одной минуты. Aurora также поддерживает переадресацию записи, что позволяет вторичным кластерам в глобальном
операторы пересылки базы данных SQL, которые выполняют операции записи в первичный кластер.запись локальных маршрутов стратегии записывает в
ближайший регион (точно так же, как и читает).
Глобальные таблицы Amazon DynamoDB позволяют реализовать такую стратегию.
разрешение чтения и записи из каждого региона вашей глобальной таблицы
развертывается в. Глобальные таблицы Amazon DynamoDB используют
последний писатель побеждает примирение между
одновременные обновления.Стратегия записи с секционированием назначает
записывает в определенный регион на основе ключа раздела (например,
идентификатор пользователя), чтобы избежать конфликтов записи. Репликация Amazon S3
настроен
двунаправленный может быть использован для этого случая, и
в настоящее время поддерживает репликацию между двумя регионами. Когда
реализуя этот подход, обязательно включите
реплика
синхронизация модификаций на обоих сегментах A и B для
реплицировать изменения метаданных реплики, такие как доступ к объектам
контрольные списки (ACL), теги объектов или блокировки объектов на
тиражируемые объекты. Вы также можете настроить, следует ли
копировать
удалите маркеры между сегментами в вашем активном
Регионы. В дополнение к воспроизведению ваша стратегия также должна
включать резервные копии на определенный момент времени для защиты от данных
события коррупции или уничтожения.
AWS CloudFormation — это мощный инструмент для последовательного применения
развернутая инфраструктура среди учетных записей AWS в нескольких AWS
Регионы.
AWS CloudFormation StackSets расширяет эту функциональность за счет
позволяя вам создавать, обновлять или удалять стеки CloudFormation
для нескольких учетных записей и регионов с помощью одной операции.
Хотя AWS CloudFormation использует YAML или JSON для определения
Инфраструктура как код,
Комплект AWS Cloud Development Kit (AWS CDK) позволяет определять инфраструктуру
как код с использованием знакомых языков программирования. Ваш код
преобразуется в CloudFormation, который затем используется для развертывания
ресурсы в AWS.
Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.
Что такое план аварийного восстановления (DRP) и как его составить?
Аварийное восстановление
К
- Кейт Браш
- Пол Крочетти,
Старший редактор сайта
Что такое план аварийного восстановления (DRP)?
План аварийного восстановления (DRP) — это документированный структурированный подход, описывающий, как организация может быстро возобновить работу после незапланированного инцидента. DRP является неотъемлемой частью плана обеспечения непрерывности бизнеса (BCP). Он применяется к аспектам организации, которые зависят от функционирующей инфраструктуры информационных технологий (ИТ). Задача DRP — помочь организации справиться с потерей данных и восстановить функциональность системы, чтобы она могла работать после инцидента, даже если она работает на минимальном уровне.
План состоит из шагов по минимизации последствий стихийного бедствия, чтобы организация могла продолжить работу или быстро возобновить выполнение критически важных функций. Как правило, DRP включает в себя анализ бизнес-процессов и потребностей в обеспечении непрерывности. Перед созданием подробного плана организация часто проводит анализ влияния на бизнес (BIA) и анализ рисков (RA), а также устанавливает цели восстановления.
По мере того, как киберпреступность и нарушения безопасности становятся все более изощренными, организациям важно определить свои стратегии восстановления и защиты данных. Способность быстро обрабатывать инциденты может сократить время простоя и свести к минимуму финансовый и репутационный ущерб. Планы DRP также помогают организациям соблюдать нормативные требования, обеспечивая при этом четкую схему восстановления.
Некоторые типы стихийных бедствий, которые организации могут планировать, включают следующее:
- сбой приложения
- сбой связи
- отключение электроэнергии
- стихийное бедствие
- вредоносное ПО или другая кибератака
- катастрофа центра обработки данных
- строительная катастрофа
- катастрофа в кампусе
- общегородская катастрофа
- региональная катастрофа
- национальная катастрофа
- многонациональная катастрофа
Вопросы плана восстановления
В случае аварии стратегия восстановления должна начинаться на бизнес-уровне, чтобы определить, какие приложения наиболее важны для работы организации. Целевое время восстановления (RTO) описывает количество времени, в течение которого критически важные приложения могут быть отключены, обычно измеряемое в часах, минутах или секундах. Целевая точка восстановления (RPO) описывает возраст файлов, которые необходимо восстановить из хранилища резервных копий данных для возобновления нормальной работы.
Эта статья является частью
Стратегии восстановления
определяют планы организации по реагированию на инцидент, а планы аварийного восстановления описывают, как организация должна реагировать. Планы восстановления являются производными от стратегий восстановления.
Знайте семь важных элементов, которые необходимо включить в план аварийного восстановления.
При определении стратегии восстановления организации должны учитывать следующие вопросы:
- бюджет
- страховое покрытие
- ресурсы — люди и материальные средства
- позиция руководства в отношении рисков
- технология
- данные и хранилище данных
- поставщиков
- требования соответствия
Одобрение руководством стратегий восстановления имеет важное значение. Все стратегии должны соответствовать целям организации. После разработки и утверждения стратегий аварийного восстановления их можно преобразовать в планы аварийного восстановления.
Типы планов аварийного восстановления
DRP можно настроить для конкретной среды. Некоторые конкретные типы планов включают следующее:
- Виртуализированный план аварийного восстановления. Виртуализация предоставляет возможности для реализации аварийного восстановления более эффективным и простым способом. Виртуализированная среда может запускать новые экземпляры виртуальных машин за считанные минуты и обеспечивать восстановление приложений благодаря высокой доступности. Тестирование также упрощается, но план должен подтверждать, что приложения могут запускаться в режиме аварийного восстановления и возвращаться к нормальной работе в пределах RPO и RTO.
- План аварийного восстановления сети. Разработка плана восстановления сети усложняется по мере увеличения сложности сети. Важно предоставить подробную пошаговую процедуру восстановления; протестируйте его должным образом; и держите его в курсе. План должен включать информацию, относящуюся к сети, например, о ее производительности и сетевом персонале.
- План аварийного восстановления облака. Облачное аварийное восстановление может варьироваться от процедур резервного копирования файлов в облаке до полной репликации. Облачное аварийное восстановление может быть эффективным с точки зрения пространства, времени и затрат, но для поддержания плана аварийного восстановления требуется надлежащее управление. Менеджер должен знать расположение физических и виртуальных серверов. План должен касаться безопасности, что является распространенной проблемой в облаке, которую можно решить с помощью тестирования.
- План аварийного восстановления центра обработки данных. Этот тип плана ориентирован исключительно на объекты и инфраструктуру центра обработки данных. Оценка операционного риска является ключевой частью DRP центра обработки данных. Он анализирует ключевые компоненты, такие как местоположение здания, системы электропитания и защиты, безопасность и офисные помещения. План должен охватывать широкий спектр возможных сценариев.
Объем и цели планирования аварийного восстановления
Основной целью DRP является минимизация негативных последствий инцидента для бизнес-операций. План аварийного восстановления может варьироваться от базового до всеобъемлющего. Некоторые DRP могут иметь длину до 100 страниц.
Бюджеты
DR сильно различаются и меняются со временем. Организации могут воспользоваться бесплатными ресурсами, такими как онлайн-шаблоны DRP, такие как шаблон SearchDisasterRecovery ниже.
Некоторые организации, такие как Business Continuity Institute и Disaster Recovery Institute International, также предоставляют бесплатную информацию и онлайн-статьи с практическими рекомендациями.
Контрольный список плана аварийного восстановления ИТ обычно включает следующее:
- критически важные системы и сети, которые он охватывает;
- сотрудника, ответственных за эти системы и сети;
- информация RTO и RPO;
- шага для перезапуска, перенастройки и восстановления систем и сетей; и
- других экстренных мер, необходимых в случае непредвиденного инцидента.
Расположение сайта аварийного восстановления следует тщательно продумать в DRP. Расстояние — важный, но часто упускаемый из виду элемент процесса DRP. Внешнее местоположение, близкое к основному центру обработки данных, может показаться идеальным — с точки зрения стоимости, удобства, пропускной способности и тестирования. Тем не менее, отключения сильно различаются по масштабу. Серьезное региональное событие может разрушить основной центр обработки данных и его сайт аварийного восстановления, если они расположены слишком близко друг к другу.
Планирование аварийного восстановления работает вместе с планированием обеспечения непрерывности бизнеса и составляет весь процесс BCDR.
Как составить план аварийного восстановления
Процесс создания плана аварийного восстановления включает в себя больше, чем просто написание документа. Перед написанием DRP анализ рисков и анализ влияния на бизнес могут помочь определить, на чем сосредоточить ресурсы в процессе аварийного восстановления.
BIA определяет воздействие разрушительных событий и является отправной точкой для определения риска в контексте аварийного восстановления. Он также генерирует RTO и RPO. RA выявляет угрозы и уязвимости, которые могут нарушить работу систем и процессов, отмеченных в BIA.
RA оценивает вероятность разрушительного события и описывает его потенциальную серьезность.
Контрольный список DRP должен включать следующие шаги:
- установление диапазона или степени необходимого лечения и деятельности — объем восстановления;
- сбор соответствующих документов по сетевой инфраструктуре;
- выявления наиболее серьезных угроз и уязвимостей, а также наиболее критичных активов;
- просмотр истории незапланированных инцидентов и отключений, а также способов их устранения;
- , определяющий текущие процедуры аварийного восстановления и стратегии аварийного восстановления;
- идентификация группы реагирования на инциденты;
- руководство рассматривает и утверждает DRP;
- тестирование плана;
- обновление плана; и
- о проведении аудита DRP или BCP.
Планы аварийного восстановления — это живые документы. Вовлечение сотрудников — от руководства до начального уровня — повышает ценность плана.
Еще одним компонентом DRP является план связи. В этой стратегии должно быть подробно описано, как будет осуществляться внутренняя и внешняя кризисная коммуникация. Внутренняя связь включает в себя оповещения, которые можно отправлять по электронной почте, через системы пейджинговой связи, голосовые сообщения и текстовые сообщения на мобильные устройства. Примеры внутренней коммуникации включают в себя инструкции по эвакуации здания и встречи в назначенных местах, обновленную информацию о развитии ситуации и уведомления о безопасном возвращении в здание.
Внешняя связь еще более важна для BCP и включает инструкции о том, как уведомить членов семьи в случае травмы или смерти; как информировать и обновлять ключевых клиентов и заинтересованные стороны о статусе бедствия; и как обсуждать стихийные бедствия со средствами массовой информации.
Шаблон плана аварийного восстановления
Организация может начать DRP со сводки основных действий и списка важной контактной информации. Это делает наиболее важную информацию быстро и легко доступной.
В плане должны быть определены роли и обязанности членов группы аварийного восстановления, а также критерии запуска плана в действие. План должен подробно определять действия по реагированию на инциденты и восстановлению.
Другие важные элементы шаблона плана аварийного восстановления включают следующее:
- заявление о намерениях и заявление о политике аварийного восстановления;
- цели плана;
- средства аутентификации, такие как пароли;
- географические риски и факторы;
- совета по работе со СМИ;
- финансовая и юридическая информация и действия; и
- история плана.
Проверка плана аварийного восстановления
DRP подтверждены тестированием для выявления недостатков и предоставления возможности исправить проблемы до того, как произойдет авария. Тестирование может предоставить доказательства того, что план реагирования на чрезвычайные ситуации эффективен и соответствует RPO и RTO. Поскольку ИТ-системы и технологии постоянно меняются, тестирование аварийного восстановления также помогает обеспечить актуальность плана аварийного восстановления.
Причины отказа от тестирования DRP включают бюджетные ограничения, нехватку ресурсов и отсутствие одобрения руководства. Тестирование аварийного восстановления требует времени, ресурсов и планирования. Это также может быть рискованно, если в тесте используются живые данные.
Тестирование
DR различается по сложности. При обзоре плана подробное обсуждение DRP позволяет выявить недостающие элементы и несоответствия. В настольном тесте участники шаг за шагом проходят запланированные действия, чтобы продемонстрировать, знают ли члены группы аварийного восстановления свои обязанности в чрезвычайной ситуации. В имитационном тесте используются такие ресурсы, как сайты восстановления и системы резервного копирования, что, по сути, является полномасштабным тестом без фактического аварийного переключения.
План управления инцидентами и план аварийного восстановления
План управления инцидентами (IMP) — или план реагирования на инциденты — также должен быть включен в DRP; вместе они создают комплексную стратегию защиты данных. Цель обоих планов — свести к минимуму влияние неожиданного инцидента, восстановиться после него и как можно быстрее вернуть организацию к нормальному уровню производительности. Однако IMP и DRP — это не одно и то же.
Основное различие между планом управления инцидентами и планом аварийного восстановления заключается в их основных целях. IMP фокусируется на защите конфиденциальных данных во время события и определяет объем действий, которые необходимо предпринять во время инцидента, включая конкретные роли и обязанности группы реагирования на инциденты.
Напротив, DRP фокусируется на определении целей восстановления и шагов, которые необходимо предпринять, чтобы вернуть организацию в рабочее состояние после возникновения инцидента.
Узнайте, что требуется для разработки плана аварийного восстановления с учетом облака и облачных сервисов.
Последнее обновление: май 2022 г.
Продолжить чтение О плане аварийного восстановления (DRP)
- 10 шагов для разработки оптимального плана аварийного восстановления ИТ
- 4 компонента плана аварийного восстановления для подготовки к кризису
- Бесплатный шаблон плана обеспечения непрерывности бизнеса и руководство
- 6 шагов к успешному плану аварийного восстановления сети
- Что включить в план тестирования аварийного восстановления
Копните глубже в планирование аварийного восстановления и управление им
виртуальное аварийное восстановление
Автор: Пол Крочетти
Что такое BCDR? Руководство по обеспечению непрерывности бизнеса и аварийному восстановлению
Автор: Джон Мур
анализ влияния на бизнес (BIA)
Автор: Пол Кирван
Планирование аварийного восстановления в облачную эпоху: техническое обслуживание и постоянное совершенствование
Автор: Пол Кирван
Резервное копирование данных
-
BackupLabs разрабатывает резервное копирование SaaS для недостаточно защищенных приложенийНовый специалист по резервному копированию SaaS появляется из скрытности для защиты данных в таких приложениях, как Trello, GitHub и GitLab, генеральный директор Роб .
.. -
CloudCasa планирует отделиться от Catalogic как независимая компанияРастущее число корпоративных пользователей Kubernetes предоставляет возможность CloudCasa, в настоящее время являющемуся подразделением Catalogic, с …
-
Защита данных для приложений на основе SaaS находится в стадии разработкиОрганизации с приложениями на основе SaaS по-прежнему полагаются на поставщиков для защиты данных, даже несмотря на то, что поставщики …
Хранение
-
Pure выпускает новый FlashBlade//E на рынок неструктурированных данныхКомпания Pure Storage расширила свои предложения по хранению данных с помощью FlashBlade//E, предназначенного для рынка неструктурированных данных, по стоимости приобретения…
-
Как оптимизировать управление хранилищем данныхУправление данными управляет доступностью, удобством использования, целостностью и безопасностью данных.
Следуйте этим рекомендациям по управлению … -
Vast Data расширяет службы данных для файлов и объектовVast Data Universal Storage предоставляет службы данных, включая набор производительности, каталогизацию метаданных, улучшенную безопасность, контейнер…
Безопасность
-
13 лучших практик реагирования на инциденты для вашей организацииПрограмма реагирования на инциденты обеспечивает быстрое и эффективное устранение событий безопасности, как только они происходят. Эти лучшие …
-
Новая национальная стратегия кибербезопасности нацелена на программы-вымогатели39-страничная Национальная стратегия кибербезопасности администрации Байдена-Харриса охватывает несколько областей, включая борьбу с программами-вымогателями …
-
Атаки программ-вымогателей разорили громкие имена в февралеНесмотря на то, что инциденты с программами-вымогателями, похоже, уменьшаются, несколько известных организаций, включая Dole, Dish Network и США.
